Fiabilidad y significación estadística. Términos y conceptos básicos de estadística médica.
Significancia estadística
Los resultados obtenidos mediante un procedimiento de investigación particular se denominan Estadísticamente significante, si la probabilidad de que ocurran aleatoriamente es muy pequeña. Este concepto se puede ilustrar con el ejemplo de lanzar una moneda al aire. Supongamos que se lanza la moneda 30 veces; Salió cara 17 veces y cruz 13 veces. Lo hace significativo desviación de este resultado del esperado (15 caras y 15 cruces), ¿o es esta desviación aleatoria? Para responder a esta pregunta, puedes, por ejemplo, lanzar la misma moneda muchas veces, 30 veces seguidas, y al mismo tiempo observar cuántas veces se repite la proporción de “cara” a “cruz” de 17:13. El análisis estadístico nos salva de este tedioso proceso. Con su ayuda, después de los primeros 30 lanzamientos de una moneda, se puede estimar el número posible de apariciones aleatorias de 17 “caras” y 13 “cruces”. Esta evaluación se denomina enunciado probabilístico.
En la literatura científica sobre psicología industrial-organizacional, un enunciado probabilístico en forma matemática se denota mediante la expresión R(probabilidad)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0,01). Este hecho es importante para comprender la literatura, pero no debe interpretarse como que no tiene sentido realizar observaciones que no cumplan con estos estándares. Los llamados resultados de investigación no significativos (observaciones que pueden obtenerse por casualidad) más una a cinco veces de cada 100) puede ser muy útil para identificar tendencias y como guía para futuras investigaciones.
También cabe señalar que no todos los psicólogos están de acuerdo con los estándares y procedimientos tradicionales (p. ej., Cohen, 1994; Sauley y Bedeian, 1989). Los problemas de medición son en sí mismos tema principal el trabajo de muchos investigadores que estudian la precisión de los métodos de medición y los supuestos que subyacen a los métodos y estándares existentes, así como el desarrollo de nuevos médicos e instrumentos. Quizás en algún momento en el futuro, la investigación con este poder conduzca a cambios en los estándares tradicionales para evaluar la significancia estadística, y estos cambios ganarán una aceptación generalizada. (La Quinta División de la Asociación Estadounidense de Psicología es un grupo de psicólogos que se especializan en el estudio de la evaluación, la medición y la estadística).
En los informes de investigación, una declaración probabilística como R< 0,05, debido a algunos Estadísticas, es decir, un número que se obtiene como resultado de un determinado conjunto de procedimientos computacionales matemáticos. La confirmación probabilística se obtiene comparando estas estadísticas con datos de tablas especiales que se publican para este fin. En industrial-organizacional investigación psicológica A menudo hay estadísticas como r, F, t, r>(léase “chi cuadrado”) y R(léase "plural" R"). En cada caso, las estadísticas (un número) obtenidas del análisis de una serie de observaciones se pueden comparar con números de una tabla publicada. Después de esto, puede formular un enunciado probabilístico sobre la probabilidad de obtener aleatoriamente este número, es decir, sacar una conclusión sobre la importancia de las observaciones.
Para comprender los estudios descritos en este libro, basta con tener una comprensión clara del concepto de significancia estadística y no necesariamente saber cómo se calculan las estadísticas mencionadas anteriormente. Sin embargo, sería útil discutir un supuesto que subyace a todos estos procedimientos. Ésta es la suposición de que todas las variables observadas tienen una distribución aproximadamente normal. Además, al leer informes sobre investigaciones psicológicas industriales y organizativas, a menudo se encuentran otros tres conceptos que juegan un papel importante: en primer lugar, correlación y comunicación correlacional, en segundo lugar, variable determinante/predictiva y "ANOVA" (análisis de varianza), en - tercero, un grupo de métodos estadísticos bajo el nombre general de “metanálisis”.
FUNCIÓN PAGO. La función de significación estadística solo está disponible en planes seleccionados. Comprueba si está dentro.
Puede averiguar si existen diferencias estadísticamente significativas en las respuestas recibidas de diferentes grupos de encuestados a las preguntas de una encuesta. Para utilizar la función de significancia estadística en SurveyMonkey, debes:
- Habilite la función de significación estadística al agregar una regla de comparación a una pregunta de su encuesta. Seleccione grupos de encuestados para compararlos y ordenar los resultados de la encuesta en grupos para realizar una comparación visual.
- Examine las tablas de datos de las preguntas de su encuesta para identificar cualquier diferencia estadísticamente significativa en las respuestas recibidas de diferentes grupos de encuestados.
Ver significación estadística
Siguiendo los pasos a continuación, puede crear una encuesta que muestre significancia estadística.
1. Agregue preguntas cerradas a su encuesta
Para mostrar significancia estadística al analizar los resultados, deberá aplicar una regla de comparación a cualquier pregunta de su encuesta.
Puede aplicar la regla de comparación y calcular la significancia estadística de las respuestas si utiliza uno de los siguientes tipos de preguntas en el diseño de su encuesta:
Es necesario asegurarse de que las opciones de respuesta propuestas se puedan dividir en grupos completos. Las opciones de respuesta que seleccione para comparar cuando cree una regla de comparación se utilizarán para organizar los datos en tablas cruzadas a lo largo de la encuesta.
2. Recoge respuestas
Una vez que haya completado su encuesta, cree un recopilador para distribuirla. Hay varias maneras.
Debe recibir al menos 30 respuestas para cada opción de respuesta que planee usar en su regla de comparación para activar y ver la significación estadística.
Ejemplo de encuesta
Quiere saber si los hombres están significativamente más satisfechos con sus productos que las mujeres.
- Agregue dos preguntas de opción múltiple a su encuesta:
¿Cuál es su género? (Macho femenino)
¿Está satisfecho o insatisfecho con nuestro producto? (satisfecho, insatisfecho) - Asegúrese de que al menos 30 encuestados seleccionen "masculino" para la pregunta de género Y al menos 30 encuestados seleccionen "femenino" como género.
- Agregue una regla de comparación a la pregunta "¿Cuál es su género?" y seleccione ambas opciones de respuesta según sus grupos.
- Utilice la tabla de datos debajo del cuadro de preguntas "¿Está satisfecho o insatisfecho con nuestro producto?" para ver si alguna opción de respuesta muestra una diferencia estadísticamente significativa
¿Qué es una diferencia estadísticamente significativa?
Una diferencia estadísticamente significativa significa que el análisis estadístico ha determinado que existen diferencias significativas entre las respuestas de un grupo de encuestados y las respuestas de otro grupo. La significación estadística significa que los números obtenidos son significativamente diferentes. Este conocimiento le será de gran ayuda en el análisis de datos. Sin embargo, usted determina la importancia de los resultados obtenidos. Eres tú quien decide cómo interpretar los resultados de la encuesta y qué acciones se deben tomar en base a ellos.
Por ejemplo, recibe más quejas de clientas que de clientes masculinos. ¿Cómo podemos determinar si esa diferencia es real y si es necesario tomar medidas al respecto? Uno de grandes maneras Comprobar tus observaciones consiste en realizar una encuesta que te mostrará si los compradores masculinos están realmente mucho más satisfechos con tu producto. Utilizando una fórmula estadística, nuestra función de significación estadística le permitirá determinar si su producto es realmente mucho más atractivo para los hombres que para las mujeres. Esto le permitirá tomar medidas basadas en hechos en lugar de conjeturas.
Diferencia estadísticamente significativa
Si sus resultados están resaltados en la tabla de datos, significa que los dos grupos de encuestados son significativamente diferentes entre sí. El término "significativo" no significa que los números resultantes tengan ninguna importancia o significado particular, sólo que existe una diferencia estadística entre ellos.
Ninguna diferencia estadísticamente significativa
Si sus resultados no están resaltados en la tabla de datos correspondiente, esto significa que, aunque puede haber una diferencia en las dos cifras que se comparan, no existe una diferencia estadística entre ellas.
Las respuestas sin diferencias estadísticamente significativas demuestran que no hay diferencias significativas entre los dos ítems que se comparan dado el tamaño de la muestra que se utiliza, pero esto no significa necesariamente que no sean significativas. Quizás al aumentar el tamaño de la muestra se pueda identificar una diferencia estadísticamente significativa.
Tamaño de la muestra
Si tiene un tamaño de muestra muy pequeño, sólo serán significativas las diferencias muy grandes entre los dos grupos. Si tiene un tamaño de muestra muy grande, tanto las diferencias pequeñas como las grandes se considerarán significativas.
Sin embargo, si dos números son estadísticamente diferentes, esto no significa que la diferencia entre los resultados tenga algún significado práctico para usted. Tendrá que decidir usted mismo qué diferencias son significativas para su encuesta.
Calcular la importancia estadística
Calculamos la significación estadística utilizando un nivel de confianza estándar del 95%. Si una opción de respuesta se muestra como estadísticamente significativa, significa que solo por casualidad o debido a un error de muestreo hay menos del 5% de probabilidad de que ocurra la diferencia entre los dos grupos (a menudo se muestra como: p<0,05).
Para calcular diferencias estadísticamente significativas entre grupos, utilizamos las siguientes fórmulas:
|
Parámetro |
Descripción | |
|---|---|---|
| a1 | El porcentaje de participantes del primer grupo que respondieron la pregunta de cierta manera, multiplicado por el tamaño de la muestra de este grupo. | |
| b1 | El porcentaje de participantes del segundo grupo que respondieron la pregunta de cierta manera, multiplicado por el tamaño de la muestra de este grupo. | |
| Proporción de muestra agrupada (p) | La combinación de dos acciones de ambos grupos. | |
| Error estándar (SE) | Un indicador de en qué medida su participación difiere de la participación real. Un valor más bajo significa que la fracción está cerca de la fracción real, un valor más alto significa que la fracción es significativamente diferente de la fracción real. | |
| Estadístico de prueba (t) | Estadística de prueba. El número de desviaciones estándar en las que un valor dado difiere de la media. | |
| Significancia estadística | Si el valor absoluto del estadístico de prueba es mayor que 1,96* desviaciones estándar de la media, se considera una diferencia estadísticamente significativa. |
*1,96 es el valor utilizado para el nivel de confianza del 95% porque el 95% del rango manejado por la función de distribución t de Student se encuentra dentro de 1,96 desviaciones estándar de la media.
Ejemplo de cálculo
Siguiendo con el ejemplo anterior, averigüemos si el porcentaje de hombres que dicen estar satisfechos con su producto es significativamente mayor que el porcentaje de mujeres.
Digamos que 1000 hombres y 1000 mujeres participaron en su encuesta y el resultado de la encuesta fue que el 70% de los hombres y el 65% de las mujeres dicen que están satisfechos con su producto. ¿El nivel del 70% es significativamente mayor que el nivel del 65%?
Sustituya los siguientes datos de la encuesta en las fórmulas dadas:
- p1 (% de hombres satisfechos con el producto) = 0,7
- p2 (% de mujeres satisfechas con el producto) = 0,65
- n1 (número de hombres encuestados) = 1000
- n2 (número de mujeres entrevistadas) = 1000
Dado que el valor absoluto del estadístico de prueba es mayor que 1,96, significa que la diferencia entre hombres y mujeres es significativa. En comparación con las mujeres, los hombres tienen más probabilidades de estar satisfechos con su producto.
Ocultar significación estadística
Cómo ocultar la significación estadística para todas las preguntas
- Haga clic en la flecha hacia abajo a la derecha de la regla de comparación en la barra lateral izquierda.
- selecciona un artículo Editar regla.
- Deshabilitar la función Mostrar significación estadística usando un interruptor.
- Clic en el botón Aplicar.
Para ocultar la significancia estadística de una pregunta, debe:
- Clic en el botón Melodía encima del diagrama de este número.
- Abre la pestaña opciones de pantalla.
- Desmarque la casilla junto a Significancia estadística.
- Clic en el botón Ahorrar.
La opción de visualización se habilita automáticamente cuando se habilita la visualización de significación estadística. Si desactiva esta opción de visualización, la visualización de significación estadística también se desactivará.
Active la función de significancia estadística cuando agregue una regla de comparación a una pregunta de su encuesta. Examine las tablas de datos de las preguntas de su encuesta para determinar si existen diferencias estadísticamente significativas en las respuestas recibidas de diferentes grupos de encuestados.
El nivel de significancia en estadística es un indicador importante que refleja el grado de confianza en la exactitud y veracidad de los datos obtenidos (predichos). El concepto se utiliza ampliamente en diversos campos: desde la realización de investigaciones sociológicas hasta la prueba estadística de hipótesis científicas.
Definición
El nivel de significancia estadística (o resultado estadísticamente significativo) muestra la probabilidad de que los indicadores estudiados ocurran por casualidad. La importancia estadística general de un fenómeno se expresa mediante el coeficiente de valor p (nivel p). En cualquier experimento u observación, existe la posibilidad de que los datos obtenidos se deban a errores de muestreo. Esto es especialmente cierto en el caso de la sociología.
Es decir, un valor estadísticamente significativo es un valor cuya probabilidad de ocurrencia aleatoria es extremadamente pequeña o tiende al extremo. El extremo en este contexto es el grado en que las estadísticas se desvían de la hipótesis nula (una hipótesis cuya coherencia se prueba con los datos de muestra obtenidos). En la práctica científica, el nivel de significancia se selecciona antes de la recopilación de datos y, por regla general, su coeficiente es 0,05 (5%). Para sistemas donde los valores precisos son extremadamente importantes, esta cifra puede ser 0,01 (1%) o menos.

Fondo
El concepto de nivel de significancia fue introducido por el estadístico y genetista británico Ronald Fisher en 1925, cuando estaba desarrollando una técnica para probar hipótesis estadísticas. Al analizar cualquier proceso, existe una cierta probabilidad de que se produzcan determinados fenómenos. Las dificultades surgen cuando se trabaja con porcentajes pequeños (o no obvios) de probabilidades que caen bajo el concepto de "error de medición".
Cuando se trabaja con datos estadísticos que no son lo suficientemente específicos para probarlos, los científicos se enfrentan al problema de la hipótesis nula, que "impide" operar con cantidades pequeñas. Fisher propuso que tales sistemas determinen la probabilidad de eventos al 5% (0,05) como un corte de muestreo conveniente, lo que permite rechazar la hipótesis nula en los cálculos.

Introducción de probabilidades fijas
En 1933, los científicos Jerzy Neumann y Egon Pearson recomendaron en sus trabajos que se estableciera de antemano (antes de la recopilación de datos) un cierto nivel de significancia. Los ejemplos del uso de estas reglas son claramente visibles durante las elecciones. Digamos que hay dos candidatos, uno de los cuales es muy popular y el otro es poco conocido. Es obvio que el primer candidato ganará las elecciones y las posibilidades del segundo tienden a cero. Se esfuerzan, pero no son iguales: siempre existe la posibilidad de fuerza mayor, información sensacionalista, decisiones inesperadas que pueden cambiar los resultados electorales previstos.
Neyman y Pearson coincidieron en que el nivel de significancia de Fisher de 0,05 (indicado por α) era el más apropiado. Sin embargo, el propio Fischer se opuso en 1956 a fijar este valor. Creía que el nivel de α debería fijarse según circunstancias específicas. Por ejemplo, en física de partículas es 0,01.

valor de nivel p
El término valor p fue utilizado por primera vez por Brownlee en 1960. El P-level (p-value) es un indicador que está inversamente relacionado con la veracidad de los resultados. El coeficiente de valor p más alto corresponde al nivel más bajo de confianza en la relación muestreada entre variables.
Este valor refleja la probabilidad de errores asociados con la interpretación de los resultados. Supongamos nivel p = 0,05 (1/20). Muestra una probabilidad del cinco por ciento de que la relación entre las variables encontradas en la muestra sea solo una característica aleatoria de la muestra. Es decir, si esta dependencia está ausente, entonces con experimentos similares repetidos, en promedio, en cada vigésimo estudio se puede esperar la misma o mayor dependencia entre las variables. El nivel p suele verse como un "margen" para la tasa de error.
Por cierto, es posible que el valor p no refleje la relación real entre variables, sino que solo muestra un cierto valor promedio dentro de los supuestos. En particular, el análisis final de los datos también dependerá de los valores seleccionados de este coeficiente. En el nivel p = 0,05 habrá algunos resultados y con un coeficiente igual a 0,01 habrá resultados diferentes.

Prueba de hipótesis estadísticas
El nivel de significación estadística es especialmente importante al probar hipótesis. Por ejemplo, al calcular una prueba bilateral, la región de rechazo se divide igualmente en ambos extremos de la distribución de muestreo (en relación con la coordenada cero) y se calcula la verdad de los datos resultantes.
Supongamos que, al monitorear un determinado proceso (fenómeno), resultó que la nueva información estadística indica pequeños cambios en relación con los valores anteriores. Al mismo tiempo, las discrepancias en los resultados son pequeñas, no obvias, pero importantes para el estudio. El especialista se enfrenta a un dilema: ¿realmente se están produciendo cambios o se trata de errores de muestreo (inexactitud en las mediciones)?
En este caso, utilizan o rechazan la hipótesis nula (atribuyen todo a un error, o reconocen el cambio en el sistema como un hecho consumado). El proceso de resolución de problemas se basa en la relación entre la significancia estadística general (valor p) y el nivel de significancia (α). Si nivel p< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Valores utilizados
El nivel de significancia depende del material que se esté analizando. En la práctica, se utilizan los siguientes valores fijos:
- α = 0,1 (o 10%);
- α = 0,05 (o 5%);
- α = 0,01 (o 1%);
- α = 0,001 (o 0,1%).
Cuanto más precisos sean los cálculos necesarios, menor será el coeficiente α que se utilice. Naturalmente, los pronósticos estadísticos en física, química, productos farmacéuticos y genética requieren mayor precisión que en ciencias políticas y sociología.

Umbrales de importancia en áreas específicas
En campos de alta precisión como la física de partículas y la fabricación, la significancia estadística a menudo se expresa como la relación entre la desviación estándar (indicada por el coeficiente sigma - σ) en relación con una distribución de probabilidad normal (distribución gaussiana). σ es un indicador estadístico que determina la dispersión de los valores de una determinada cantidad en relación con las expectativas matemáticas. Se utiliza para trazar la probabilidad de eventos.
Dependiendo del campo de conocimiento, el coeficiente σ varía mucho. Por ejemplo, al predecir la existencia del bosón de Higgs, el parámetro σ es igual a cinco (σ = 5), lo que corresponde a un valor p = 1/3,5 millones. En los estudios del genoma, el nivel de significancia puede ser 5 × 10 - 8, lo cual no es raro en estas áreas.
Eficiencia
Hay que tener en cuenta que los coeficientes α y el valor p no son características exactas. Cualquiera que sea el nivel de importancia en las estadísticas del fenómeno en estudio, no es una base incondicional para aceptar la hipótesis. Por ejemplo, cuanto menor sea el valor de α, mayor será la probabilidad de que la hipótesis que se establece sea significativa. Sin embargo, existe riesgo de error, lo que reduce el poder estadístico (significancia) del estudio.
Los investigadores que se centran únicamente en resultados estadísticamente significativos pueden llegar a conclusiones erróneas. Al mismo tiempo, es difícil verificar su trabajo, ya que aplican supuestos (que en realidad son los valores α y p). Por lo tanto, siempre se recomienda, además de calcular la significación estadística, determinar otro indicador: la magnitud del efecto estadístico. El tamaño del efecto es una medida cuantitativa de la fuerza de un efecto.
Más recientemente, Vladimir Davydov escribió una publicación en Facebook sobre las pruebas A/B o MVT, que generó muchas preguntas.
Normalmente, realizar pruebas A/B o MVT en sitios web es algo muy difícil. Aunque a los “landers” les parece que esto es elemental, porque “es lo mismo, hay programas especiales, eh”.
Si decides probar el contenido web, recuerda:
1. En primer lugar, es necesario aislar una audiencia de igual tamaño y calidad. Realizar pruebas A/A. La gran mayoría de las pruebas realizadas por agencias en línea o especialistas en marketing de Internet sin experiencia son incorrectas. Precisamente por el motivo de que el contenido se prueba en diferentes audiencias.
2. Realizar docenas o, mejor aún, cientos de pruebas durante varios meses. No vale la pena probar 2 o 3 versiones de una página durante una semana.
3. Recuerda que también puedes realizar pruebas en formato MVT (es decir, muchas opciones), y no solo A y B.
4. Analice estadísticamente la matriz de datos con los resultados de las pruebas (Excel está absolutamente bien, también puede usar SPSS). ¿Están los resultados dentro del margen de error, cuánto se desvían y cómo dependen del tiempo? Si, por ejemplo, en el primer punto de la prueba A/A recibió fuertes desviaciones de una opción con respecto a otra, esto es un fracaso y no puede realizar más pruebas.
5. No es necesario probarlo todo. Esto no es entretenimiento (a menos que realmente no tengas nada más que hacer). Tiene sentido probar sólo lo que, desde el punto de vista del marketing y el análisis empresarial, puede conducir a resultados notables. Y también algo a partir de lo cual se puedan medir los resultados. Por ejemplo, decidió aumentar el tamaño de fuente en el sitio web, probó una página con una fuente más grande durante un par de semanas y las ventas aumentaron. ¿Qué quiere decir esto? Eso no es nada para mí (ver párrafos anteriores).
6. Es necesario probar caminos completos. Es decir, no basta con tomar y probar la página de compra (o alguna acción en el sitio); es necesario probar esas páginas y los pasos que conducen a esta página de conversión final.
La pregunta se hizo en los comentarios:
“¿Cómo determinar el ganador? Aquí probamos el título en una página que se vende "de frente". ¿Qué diferencia de conversión debe haber entre A y B para declarar ganador?
La respuesta de Vladimir:
En primer lugar, es necesario realizar experimentos aislados a largo plazo (la regla básica de cualquier evaluación estadística). En segundo lugar, todo se reduce inevitablemente a la estadística y las matemáticas (por eso recomiendo Excel y spss o análogos gratuitos): necesitamos calcular la probabilidad de confianza de que la diferencia de valores signifique algo. Hay un buen artículo (uno de muchos). Allí toman transacciones de GA basándose en pruebas de Optimizelyhttps://www.distilled.net/uploads/ga_transactions.png , compare las transacciones (compras) con la distribución de campana habitual y vea si el valor promedio cae dentro del intervalo de confianza del errorhttps://www.distilled.net/uploads/t-test_tool.png
¿Le gustaría recibir una oferta nuestra?
Iniciar la cooperaciónEl papel de la importancia estadística en el aumento de las conversiones: 6 cosas que necesita saber
1. Exactamente lo que significa

"El cambio nos permitió lograr un aumento del 20 % en la conversión con un nivel de confianza del 90 %". Lamentablemente, esta afirmación no equivale en absoluto a otra muy similar: “Las posibilidades de aumentar la conversión en un 20% son del 90%”. Entonces, ¿de qué se trata realmente?
El 20% es un aumento que registramos según los resultados de las pruebas realizadas en una de las muestras. Si empezáramos a fantasear y especular, podríamos imaginar que este crecimiento podría persistir permanentemente, si continuáramos probando indefinidamente. Pero esto no significa que con un 90% de probabilidad obtendremos un aumento del veinte por ciento en la conversión, o un aumento de “al menos” un 20%, o “aproximadamente” un 20%.
El 90% es la probabilidad de cualquier cambio en la conversión. En otras palabras, si ejecutamos diez pruebas A/B para obtener este resultado y decidimos ejecutar las diez hasta el infinito, entonces una de ellas (dado que la probabilidad de cambio es del 90 %, entonces queda el 10 % para el resultado sin cambios) probablemente terminaría acercando el resultado de la “prueba posterior” a la conversión original, es decir, sin cambios. De las nueve pruebas restantes, algunas podrían mostrar un aumento muy inferior al 20%. En otros, el resultado podría superar este listón.
Si malinterpretamos estos datos, corremos un gran riesgo al “implementar” la prueba. Es fácil entusiasmarse cuando una prueba muestra altas tasas de conversión con un nivel de confianza del 95%, pero es aconsejable no esperar demasiado hasta que la prueba llegue a su conclusión lógica.
2. Cuándo utilizar
Los candidatos más obvios son las pruebas divididas A/B, pero están lejos de ser los únicos. También puede probar diferencias estadísticamente significativas entre segmentos (por ejemplo, visitas de búsqueda orgánica versus de pago) o períodos de tiempo (por ejemplo, abril de 2013 y abril de 2014).

Sin embargo, vale la pena señalar que esta correlación no implica causalidad. Cuando ejecutamos pruebas divididas, sabemos que podemos atribuir cualquier cambio en los resultados a los elementos que hacen que las páginas sean diferentes; después de todo, se tiene especial cuidado para garantizar que las páginas sean exactamente idénticas. Si compara grupos como los visitantes provenientes de la búsqueda orgánica y de pago, cualquier otro factor puede entrar en juego; por ejemplo, desde la búsqueda orgánica puede haber muchas visitas por la noche y la tasa de conversión entre los visitantes nocturnos es bastante alta. Las pruebas de significancia pueden ayudar a determinar si existe un motivo para un cambio, pero no pueden decir cuál es el motivo.
3. Cómo probar cambios en las tasas de conversión, tasas de rebote y tasas de salida
Cuando miramos los “indicadores”, en realidad estamos mirando promedios de variables binarias: alguien completó las acciones objetivo o no. Si tenemos una muestra de 10 personas con una tasa de conversión del 40%, en realidad estamos viendo una tabla como esta:

Necesitamos esta tabla, junto con el promedio, para calcular la desviación estándar, un componente clave de la significancia estadística. Sin embargo, el hecho de que cada valor en la tabla sea cero o uno nos lo hace más fácil: podemos evitar tener que copiar una lista enorme de números usando una calculadora de confianza de prueba A/B y comenzando por conocer el promedio. y tamaños de muestras. Esta es una herramienta de KissMetrics.

(¡Importante! Esta herramienta solo tiene en cuenta un lado de la distribución de probabilidad en sus cálculos. Para usar ambos lados y convertir el resultado a significación bilateral, debe duplicar la distancia desde el 100%; por ejemplo, unilateral 95 El % se vuelve bilateral 90%).
Aunque la descripción dice "Herramienta de validez de prueba A/B", también se puede utilizar para cualquier otra comparación de métricas: simplemente reemplace la conversión con la tasa de rebote o de salida. Además, se puede utilizar para comparar segmentos o períodos de tiempo; los cálculos serán los mismos.
Además, es muy adecuado para pruebas multivariadas (MVT): simplemente compare cada cambio individualmente con el original.
4. Cómo probar cambios en la factura promedio
Para probar las medias de variables no binarias, necesitamos el conjunto de datos completo, por lo que las cosas se complican un poco más aquí. Por ejemplo, queremos determinar si existe una diferencia significativa en el valor promedio del pedido para una prueba dividida A/B; este punto a menudo se omite en la optimización de la conversión, aunque para los indicadores comerciales es tan importante como la conversión misma.
Lo primero que necesitamos es obtener una lista completa de transacciones de Google Analytics para cada opción de prueba, para A y B (era, ahora). La forma más sencilla de hacerlo es crear segmentos personalizados basados en variables personalizadas para su prueba dividida y luego exportar el informe de transacciones a una hoja de cálculo de Excel. Asegúrese de que todas las transacciones estén incluidas allí, no solo las 10 filas predeterminadas.

Cuando tenga dos listas de transacciones, puede copiarlas en una herramienta como esta:
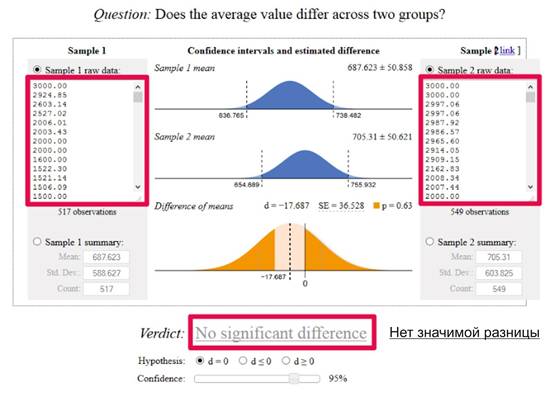
En el caso anterior, no tenemos un nivel de confianza en el nivel elegido del 95%. De hecho, si miramos la puntuación p encima del gráfico inferior de 0,63, está claro que ni siquiera tenemos un 50% de significancia: hay un 63% de posibilidades de que la diferencia entre las puntuaciones de las páginas se deba exclusivamente al azar.
5. Cómo predecir la duración requerida de una prueba dividida A/B
Evanmiller.org tiene otra herramienta útil para optimizar la conversión: una calculadora de tamaño de muestra.
Esta herramienta le permite responder a la pregunta “¿Cuánto tiempo llevará obtener resultados confiables de las pruebas?”, y no vale la pena intentar adivinar esta respuesta.

Hay algunas cosas que vale la pena señalar. Primero, la herramienta tiene un interruptor absoluto/relativo: si desea conocer la diferencia entre una tasa de conversión base del 5% y una tasa de conversión variable del 6%, será 1% absoluto (6-5=1) o 20 % en términos relativos (6/5=1,2). En segundo lugar, hay dos "controles deslizantes" en la parte inferior de la página. El inferior es responsable del nivel de significancia requerido: si su objetivo es lograr una significancia del 95%, entonces el control deslizante debe establecerse en el 5%. El control deslizante superior muestra la probabilidad de que el número de visitas requeridas a una página sea suficiente; por ejemplo, si desea saber el número de visitas necesarias para lograr un ochenta por ciento de posibilidades de encontrar una significancia del 95 %, establezca el control deslizante superior en 80% y el control deslizante inferior al 5%.
6. Qué no hacer
Hay varias formas sencillas de identificar la inadecuación de una prueba dividida, que, sin embargo, no siempre son obvias a primera vista:
A) Prueba dividida de valores ordinales no binarios
Por ejemplo, su objetivo es determinar si existe una diferencia significativa en la probabilidad de que los visitantes de los grupos originales y posteriores al cambio compren ciertos productos. Usted etiqueta los tres productos como "1", "2" y "3" y luego ingresa estos valores en los campos de prueba de significancia. Desafortunadamente, este enfoque no funcionará: el producto 2 no es el promedio de los productos 1 y 3.
B) Configuración de distribución del tráfico

Al comienzo de la prueba, decides no correr riesgos y estableces la distribución del tráfico en 90/10. Después de un tiempo, verá que el cambio no provocó un cambio notable en la conversión y moverá el control deslizante a 50/50. Pero los visitantes que regresan aún pertenecen a su grupo original, por lo que terminas en una situación en la que la versión "previa al cambio" tiene una mayor proporción de visitantes que regresan y muestran una alta probabilidad de realizar una conversión. Las cosas se complican muy rápidamente y la única forma sencilla de obtener datos en los que pueda confiar es observar a los visitantes nuevos y recurrentes por separado. Sin embargo, en este caso llevará más tiempo obtener resultados significativos. E incluso si ambos subgrupos muestran resultados significativos, ¿qué pasa si uno de ellos genera más visitantes recurrentes? En general, no es necesario hacer esto y cambiar la distribución del tráfico durante la prueba.
B) Planificación
Parece obvio, pero no compare los datos recopilados a la misma hora del día con los datos recopilados durante el día o en otros momentos del día. Si desea realizar la prueba para una hora específica del día, tiene dos opciones.
1. Maneje las solicitudes de los visitantes a lo largo del día como de costumbre, pero muéstreles la versión original de la página en un momento del día que no le interese.
2. Compare manzanas con manzanas: si solo está viendo los datos de cambios de la primera mitad del día, compárelos con los datos originales de la primera mitad del día.
Espero que algo de lo anterior le resulte útil para optimizar sus tasas de conversión. Si tiene sus propios conocimientos, compártalos en los comentarios.
Consideremos un ejemplo típico de la aplicación de métodos estadísticos en medicina. Los creadores del fármaco sugieren que aumenta la diuresis en proporción a la dosis tomada. Para probar esta hipótesis, administran a cinco voluntarios diferentes dosis del fármaco.
Según los resultados de la observación, se traza una gráfica de diuresis versus dosis (fig. 1.2A). La dependencia es visible a simple vista. Los investigadores se felicitan unos a otros por el descubrimiento y al mundo por el nuevo diurético.
De hecho, los datos sólo nos permiten afirmar de forma fiable que se observó una diuresis dosis-dependiente en estos cinco voluntarios. El hecho de que esta dependencia se manifestará en todas las personas que toman el medicamento no es más que una suposición.
zy

 Con
Con
vida No se puede decir que sea infundado; de lo contrario, ¿por qué realizar experimentos?
Pero la droga salió a la venta. Cada vez más personas lo toman con la esperanza de aumentar su producción de orina. Entonces ¿Qué vemos? Vemos la Figura 1.2B, que indica la ausencia de cualquier conexión entre la dosis del fármaco y la diuresis. Los círculos negros indican datos del estudio original. La estadística tiene métodos que nos permiten estimar la probabilidad de obtener una muestra tan “poco representativa” y, de hecho, confusa. Resulta que, en ausencia de una conexión entre la diuresis y la dosis del fármaco, la “dependencia” resultante se observaría en aproximadamente 5 de cada 1000 experimentos. Entonces, en este caso, los investigadores simplemente no tuvieron suerte. Incluso si hubieran utilizado los métodos estadísticos más avanzados, eso no les habría impedido cometer errores.
Hemos dado este ejemplo ficticio, pero nada alejado de la realidad, para no señalar la inutilidad.
ness de las estadísticas. Habla de otra cosa, del carácter probabilístico de sus conclusiones. Como resultado de aplicar el método estadístico, no obtenemos la verdad última, sino sólo una estimación de la probabilidad de un supuesto particular. Además, cada método estadístico se basa en su propio modelo matemático y sus resultados son correctos en la medida en que dicho modelo se corresponda con la realidad.
Más sobre el tema CONFIABILIDAD Y SIGNIFICADO ESTADÍSTICO:
- Diferencias estadísticamente significativas en los indicadores de calidad de vida.
- Población estadística. Características contables. El concepto de investigación continua y selectiva. Requisitos para datos estadísticos y el uso de documentos contables y de presentación de informes.
- ABSTRACTO. ESTUDIO DE CONFIABILIDAD DE LAS INDICACIONES DE TONÓMETRO PARA MEDIR LA PRESIÓN INTRAOCULAR A TRAVÉS DEL PÁRPADO 2018, 2018