Distribuciones de probabilidad típicas: la hoja de trucos del científico de datos. Distribución binomial de una variable aleatoria discreta
Sección 6. Leyes típicas de distribución y características numéricas de variables aleatorias
La forma de las funciones F (x), p (x), o la enumeración p (x i) se llama la ley de distribución de una variable aleatoria. Si bien se puede imaginar una variedad infinita de variables aleatorias, hay muchas menos leyes de distribución. Primero, diferentes variables aleatorias pueden tener exactamente las mismas leyes de distribución. Por ejemplo: sea y tome solo 2 valores 1 y -1 con probabilidades 0.5; el valor z = -y tiene exactamente la misma ley de distribución.
En segundo lugar, muy a menudo las variables aleatorias tienen leyes de distribución similares, es decir, por ejemplo, p (x) para ellas se expresa mediante fórmulas del mismo tipo, que difieren solo en una o varias constantes. Estas constantes se denominan parámetros de distribución.
Aunque en principio es posible una amplia variedad de leyes de distribución, aquí se considerarán varias de las leyes más típicas. Es importante prestar atención a las condiciones en las que surgen, los parámetros y propiedades de estas distribuciones.
una . Distribución equitativa
Este es el nombre de la distribución de una variable aleatoria, que puede tomar cualquier valor en el intervalo (a, b), y la probabilidad de que caiga en cualquier segmento dentro de (a, b) es proporcional a la longitud del segmento y no depende de su posición, y la probabilidad de valores fuera de (a, b ) es igual a 0.

Fig. 6.1 Función y densidad de distribución uniforme
Parámetros de distribución: a, b
2. Distribución normal
Distribución con densidad descrita por la fórmula
![]() (6.1)
(6.1)
llamado normal.
Parámetros de distribución: a, σ

Figura 6.2 Vista típica de densidad y función distribución normal
3. Distribución de Bernoulli
Si se realiza una serie de pruebas independientes, en cada una de las cuales el evento A puede aparecer con la misma probabilidad p, entonces el número de ocurrencias del evento es una variable aleatoria distribuida según la ley de Bernoulli, o según la ley binomial (otro nombre para la distribución).
Aquí n es el número de pruebas en la serie, m es una variable aleatoria (el número de ocurrencias del evento A), P n (m) es la probabilidad de que A suceda exactamente m veces, q = 1 - p (la probabilidad de que A no aparezca en la prueba).
Ejemplo 1: Se lanza el dado 5 veces, ¿cuál es la probabilidad de que se lancen 6 puntos dos veces?
n = 5, m = 2, p = 1/6, q = 5/6
![]()
Parámetros de distribución: n, p
4 . distribución de veneno
La distribución de Poisson se obtiene como caso límite de la distribución de Bernoulli, si p tiende a cero, yn a infinito, pero de forma que su producto se mantenga constante: np = a. Formalmente, este paso al límite conduce a la fórmula
Parámetro de asignación: a
La distribución de Poisson está sujeta a muchas variables aleatorias que se encuentran en la ciencia y la vida práctica.
Ejemplo 2: El número de llamadas a una estación de ambulancia en una hora.
Dividimos el intervalo de tiempo T (1 hora) en pequeños intervalos dt, tales que la probabilidad de dos o más llamadas durante dt es despreciable, y la probabilidad de una llamada p es proporcional a dt: p = μdt;
consideraremos la observación durante los momentos dt como pruebas independientes, el número de tales pruebas durante el tiempo T: n = T / dt;
si asumimos que las probabilidades de que lleguen llamadas no cambian dentro de una hora, entonces el número total de llamadas obedece la ley de Bernoulli con los parámetros: n = T / dt, p = μdt. Haciendo que dt tienda a cero, encontramos que n tiende a infinito, y el producto n × p permanece constante: a = n × p = μT.
Ejemplo 3: el número de moléculas de gas ideal en un cierto volumen fijo V.
Dividimos el volumen V en pequeños volúmenes dV tales que la probabilidad de encontrar dos o más moléculas en dV es despreciable, y la probabilidad de encontrar una molécula es proporcional a dV: p = μdV; consideraremos la observación de cada volumen dV como una prueba independiente, el número de tales pruebas n = V / dV; si asumimos que las probabilidades de encontrar una molécula en cualquier lugar dentro de V son las mismas, el número total de moléculas en el volumen V obedece la ley de Bernoulli con los parámetros: n = V / dV, p = μdV. Haciendo que dV tienda a cero, encontramos que n tiende a infinito, y el producto n × p permanece constante: a = n × p = μV.
Características numéricas de las variables aleatorias
una . Expectativa (media)
Definición:
La esperanza matemática se llama
![]() & nota (6.4)
& nota (6.4)
La suma se toma sobre todos los valores que toma la variable aleatoria. La serie debe ser absolutamente convergente (de lo contrario dicen que la variable aleatoria no tiene expectativa matemática)
![]() ; & nota (6.5)
; & nota (6.5)
La integral debe ser absolutamente convergente (de lo contrario dicen que la variable aleatoria no tiene expectativa matemática)
Propiedades de expectativa matemática:
una. Si C es un valor constante, entonces MC = C
B. MCx = CMx
C. La expectativa matemática de la suma de variables aleatorias siempre es igual a la suma de sus expectativas matemáticas: M (x + y) = Mx + My d. Se introduce el concepto de expectativa matemática condicional. Si una variable aleatoria toma sus valores x i con diferentes probabilidades p (x i / H j) bajo diferentes condiciones H j, entonces se determina la expectativa matemática condicional
cómo ![]() o
o ![]() ; & nota (6.6)
; & nota (6.6)
Si se conocen las probabilidades de los eventos H j, el
valor esperado: ![]() ; & nota (6.7)
; & nota (6.7)
Ejemplo 4: En promedio, ¿cuántas veces se debe lanzar una moneda antes de que caiga el primer escudo de armas? Este problema se puede resolver "de frente"
| x yo | 1 2 3 ... k .. | |
| p (xi): & nbsp | | , |
pero esta cantidad aún debe calcularse. Puede hacerlo más fácilmente usando los conceptos de expectativa matemática total y condicional. Considere las hipótesis H 1: el escudo de armas se cayó la primera vez, H 2: la primera vez que no se cayó. Obviamente, p (H 1) = p (H 2) = ½; Mx/H1 = 1;
Мx / Í 2 es 1 más que el valor esperado total requerido, ya que después del primer lanzamiento de la moneda, la situación no ha cambiado, pero una vez que ya se ha lanzado. Usando la fórmula para la expectativa matemática completa, tenemos Mx = Mx / H 1 × p (H 1) + Mx / H 2 × p (H 2) = 1 × 0.5 + (Mx + 1) × 0.5, resolviendo la ecuación para Mx, inmediatamente obtenemos Mx = 2.
mi. Si f(x) es una función de una variable aleatoria x, entonces se define el concepto de expectativa matemática de una función de una variable aleatoria:
Para una variable aleatoria discreta: ![]() ; & nota (6.8)
; & nota (6.8)
La suma se toma sobre todos los valores que toma la variable aleatoria. La serie debe ser absolutamente convergente.
Para una variable aleatoria continua: ![]() ; & nota (6.9)
; & nota (6.9)
La integral debe ser absolutamente convergente.
2. Varianza de una variable aleatoria
Definición:
La varianza de una variable aleatoria x es la expectativa matemática del cuadrado de la desviación del valor de su expectativa matemática: Dx = M (x-Mx) 2
Para una variable aleatoria discreta: ![]() ; & nota (6.10)
; & nota (6.10)
La suma se toma sobre todos los valores que toma la variable aleatoria. La serie debe ser convergente (de lo contrario se dice que la variable aleatoria no tiene varianza)
Para una variable aleatoria continua: ![]() ; & nota (6.11)
; & nota (6.11)
La integral debe ser convergente (de lo contrario se dice que la variable aleatoria no tiene varianza)
Propiedades de dispersión:
una. Si C es un valor constante, entonces DC = 0
B. Dх = С 2 Dх
C. La varianza de la suma de variables aleatorias siempre es igual a la suma de sus varianzas solo si estos valores son independientes (determinación de variables independientes)
D. Para calcular la varianza, es conveniente utilizar la fórmula:
Dx = Mx 2 - (Mx) 2 (6,12)
Relación de características numéricas
y parámetros de distribuciones típicas
| distribución | parámetros | fórmula | MX | Dx |
| uniforme | un, b | (b + a) / 2 | (b-a) 2/12 | |
| normal | un, σ | a | σ 2 | |
| Bernoulli | norte, pag | notario público | npq | |
| veneno | a | a | a |
Una distribución de probabilidad es una medida de probabilidad en un espacio medible.
Sea W un conjunto no vacío de naturaleza arbitraria y Ƒ -s-álgebra sobre W, es decir, la colección de subconjuntos de W que contiene a W mismo, el conjunto vacío Æ, y cerrado con respecto a un conjunto como máximo contable de operaciones teóricas de conjuntos (esto significa que para cualquier A Î Ƒ conjunto = W \ A pertenece de nuevo Ƒ y si A 1 , A 2,… Î Ƒ , entonces Ƒ y Ƒ ). Par (W, Ƒ ) se llama espacio medible. Función no negativa P ( A) definido para todos A Î Ƒ , se denomina medida de probabilidad, probabilidad, P. de probabilidades, o simplemente P., si P (W) = 1 y P es contablemente aditivo, es decir, para cualquier secuencia A 1 , A 2,… Î Ƒ tal que un yo ∩ una j= Æ para todos I ¹ j, la igualdad P () = P ( un yo). Trío (W, Ƒ , P) se llama espacio de probabilidad. El espacio de probabilidad es el concepto inicial de la teoría axiomática de la probabilidad propuesta por A.N. Kolmogorov a principios de la década de 1930.
En cada espacio de probabilidad, se pueden considerar funciones medibles (reales) X = X(w), wÎW, es decir, funciones tales que (w: X(w) Î B} Î Ƒ para cualquier subconjunto de Borel B muy recto R... Mensurabilidad de una función X es equivalente a (w: X(w)< X} Î Ƒ para cualquier válido X... Las funciones medibles se llaman variables aleatorias. Cada variable aleatoria X definido en el espacio de probabilidad (W, Ƒ , P), genera P. probabilidades
P X
(B) = PAG ( XÎ B) = P ((w: X(w) Î B}), B Î Ɓ
,
en un espacio medible ( R,
Ɓ
), donde Ɓ
R, y la función de distribución
F X(X) = PAG ( X < X) = P ((w: X(w)< X}), -¥ < X <¥,
que se denominan P. probabilidades y la función de distribución de una variable aleatoria X.
Función de distribución F cualquier variable aleatoria tiene las propiedades
1. F(X) no decreciente,
2. F(- ¥) = 0, F(¥) = 1,
3. F(X) es continua por la izquierda en cada punto X.
A veces, en la definición de la función de distribución, la desigualdad< заменяется неравенством £; в этом случае функция распределения является непрерывной справа. В содержательных утверждениях теории вероятностей не важно, непрерывна функция распределения слева или справа, важны лишь положения ее точек разрыва X(si lo hay) y los incrementos F(X+0) - F(X-0) en estos puntos; Si F X, entonces este incremento es P ( X = X).
Cualquier función F con propiedades 1. - 3. se llama función de distribución. La correspondencia entre distribuciones en ( R, Ɓ ) y las funciones de distribución son uno a uno. Para cualquier r. PAGS sobre el ( R, Ɓ ) su función de distribución está determinada por la igualdad F(X) = PAGS((-¥, X)), -¥ < X <¥, а для любой функции распределения F correspondiente a su R. PAGS la función F 1 (X) aumenta linealmente de 0 a 1. Para construir la función F 2 (X) el segmento se divide en un segmento, un intervalo (1/3, 2/3) y un segmento. Función F 2 (X) en el intervalo (1/3, 2/3) es igual a 1/2 y crece linealmente de 0 a 1/2 y de 1/2 a 1 en los intervalos y, respectivamente. Este proceso continúa y la función f norte+1 se obtiene mediante la siguiente transformación de la función f norte, norte³ 2. En intervalos donde la función f norte(X) es constante, f norte +1 (X) partidos f norte(X). Cada segmento donde la función f norte(X) aumenta linealmente desde a antes de B, se divide en un segmento, un intervalo (a + (a - b) / 3, a + 2 (b - a) / 3) y un segmento. En el intervalo especificado f norte +1 (X) es igual a ( a + B) / 2, y en los intervalos indicados f norte +1 (X) aumenta linealmente desde a antes de ( a + B) / 2 y desde ( a + B) / 2 a B respectivamente. Por cada 0 € X£ 1 secuencia f norte(X), norte= 1, 2, ..., converge a algún número F(X). Secuencia de funciones de distribución f norte, norte= 1, 2, ..., es equicontinua, por lo tanto, la función de distribución límite F(X) es continuo. Esta función es constante en un conjunto contable de intervalos (los valores de la función en diferentes intervalos son diferentes), en los que no hay puntos de crecimiento, y la longitud total de estos intervalos es 1. Por lo tanto, la medida de Lebesgue de la establecer soporte F es igual a cero, es decir F singular.
Cada función de distribución se puede representar como
F(X) = pags C.A F ca ( X) + pags D F D ( X) + pags s F s ( X),
donde F C.A, F d y F funciones de distribución absolutamente continuas, discretas y singulares, y la suma de números no negativos pags C.A, pags d y p s es igual a uno. Esta representación se llama desarrollo de Lebesgue y las funciones F C.A, F d y F s - componentes de descomposición.
Una función de distribución se llama simétrica si F(-X) = 1 - F(X+ 0) para
X> 0. Si una función de distribución simétrica es absolutamente continua, entonces su densidad es una función par. Si una variable aleatoria X tiene una distribución simétrica, entonces las variables aleatorias X y - X igualmente distribuido. Si la función de distribución simétrica F(X) es continua en cero, entonces F(0) = 1/2.
Entre los utilizados con frecuencia en la teoría de la probabilidad R. absolutamente continua - R. uniforme, R. normal (R. Gauss), R. exponencial y R. Cauchy.
R. se llama uniforme en el intervalo ( a, B) (o en el segmento [ a, B], o entre [ a, B) y ( a, B]) si su densidad es constante (e igual a 1 / ( B - a)) sobre el ( a, B) y es igual a cero fuera de ( a, B). La R uniforme más utilizada en (0, 1), su función de distribución F(X) es igual a cero para X£ 0 es igual a uno para X> 1 y F(X) = X en 0< X£ 1. Uniforme R. en (0, 1) tiene una variable aleatoria X(w) = w en el espacio de probabilidad que consta del intervalo (0, 1), la colección de subconjuntos de Borel de este intervalo y la medida de Lebesgue. Este espacio probabilístico corresponde al experimento “lanzar un punto w al azar en el intervalo (0, 1)”, donde la palabra “al azar” significa igualdad (“igual oportunidad”) de todos los puntos desde (0, 1). Si en el espacio de probabilidad (W, Ƒ , P) hay una variable aleatoria X con P. uniforme en (0, 1), luego en él para cualquier función de distribución F hay una variable aleatoria Y, para la cual la función de distribución año fiscal coincide con F... Por ejemplo, la función de distribución de una variable aleatoria Y = F -1 (X) partidos F... Aquí F -1 (y) = inf ( X: F(X) > y}, 0 < y < 1; если функция F(X) es continua y estrictamente monótona en toda la línea real, entonces F-1 - función inversa F.
R. normal con parámetros ( a, s 2), - ¥< a < ¥, s 2 >0, se llama P. con densidad, - ¥< X < ¥. Чаще всего используется нормальное Р. с параметрами a= 0 y s 2 = 1, que se llama normal estándar P., su función de distribución F ( X) no se expresa en términos de la superposición de funciones elementales y hay que usar su representación integral F ( X) =, -¥ < X < ¥. Для фунции распределения F(X) compiló tablas detalladas que eran necesarias antes de la moderna Ingeniería Informática(los valores de la función F ( X) se puede obtener utilizando tablas especiales. funciones erf ( X)), los valores de F ( X) por X> 0 se puede obtener usando la suma de la serie
,
y para X < 0 можно воспользоваться симметричностью F(X). Valores de la función de distribución normal con parámetros a y s 2 se puede obtener por el hecho de que coincide con F (( X - a) / s). Si X 1 y X 2 independientes normalmente distribuidos con parámetros a 1, s 1 2 y a 2, s 2 2 son variables aleatorias, entonces la distribución de su suma X 1 + X 2 también está bien con los parámetros a= a 1 + a 2 y s 2 = s 1 2 + s 2 2. La afirmación también es cierta, en cierto sentido, al contrario: si la variable aleatoria X distribuida normalmente con parámetros a y s 2 y
X = X 1 + X 2, donde X 1 y X 2 son variables aleatorias independientes distintas de las constantes, entonces X 1 y X 2 tienen distribuciones normales (teorema de Cramer). Parámetros a 1, s 1 2 y a 2, s 2 2 distribuciones de variables aleatorias normales X 1 y X 2 relacionado con a y s 2 igualdades anteriores. La distribución normal estándar es el límite en el teorema del límite central.
R exponencial es una distribución con densidad pags(X) = 0 para X < 0 и pags(X) = l mi- yo X en X³ 0, donde l> 0 es un parámetro, su función de distribución F(X) = 0 para X£ 0 y F(X) = 1 - mi- yo X en X> 0 (a veces se utilizan R. exponenciales, que difieren de la indicada por un desplazamiento a lo largo del eje real). Esta R. tiene una propiedad llamada ausencia de repercusión: si X es una variable aleatoria con R exponencial, entonces para cualquier positivo X y t
PAGS ( X > X + t | X > X) = PAG ( X > t).
Si X es el tiempo de funcionamiento de un determinado dispositivo hasta que falla, entonces la ausencia de efecto secundario significa que la probabilidad de que el dispositivo encendido en el momento 0 no falle hasta el momento X + t siempre que no se negara hasta el momento X, no depende de X... Esta propiedad se interpreta como la ausencia de "envejecimiento". La ausencia de efecto secundario es una propiedad característica de R exponencial: en la clase de distribuciones absolutamente continuas, la igualdad anterior es válida solo para R exponencial (con algún parámetro l > 0). R. exponencial aparece como R. limitante en el esquema mínimo. Dejar X 1 , X 2, ... son variables aleatorias independientes no negativas idénticamente distribuidas y por su función de distribución común F el punto 0 es el punto de crecimiento. entonces en norte® ¥ distribuciones de variables aleatorias Ynorte= min ( X 1 ,…, X norte) convergen débilmente a una distribución degenerada con un solo punto de crecimiento 0 (esto es un análogo de la ley de los grandes números). Si además asumimos que para alguna e > 0 la función de distribución F(X) en el intervalo (0, e) admite una representación y pags(tu) ®l para tu¯ 0, entonces las funciones de distribución de las variables aleatorias Z norte = norte
min ( X 1 ,…, X norte) en norte® ¥ uniformemente en - ¥< X < ¥ сходятся к экспоненциальной функции распределения с параметром l (это - аналог центральной предельной теоремы).
R. Cauchy se llama R. con densidad pags(X) = 1 / (p (1 + X 2)), - ¥< X < ¥, его функция рас-пределения F(X) = (arco X+ p / 2) / p. Esta R. apareció en el trabajo de Poisson en 1832 en relación con la solución del siguiente problema: ¿existen variables aleatorias independientes distribuidas idénticamente? X 1 , X 2, ... tal que la aritmética significa ( X 1 + … + X norte)/norte en cada norte tienen la misma R. que cada una de las variables aleatorias X 1 , X 2,...? S. Poisson descubrió que las variables aleatorias con la densidad indicada tienen esta propiedad. Para estas variables aleatorias, no se cumple el enunciado de la ley de los grandes números, en la que las medias aritméticas ( X 1 +…+ X norte)/norte con crecimiento norte degenerar. Sin embargo, esto no contradice la ley de los grandes números, ya que impone restricciones a las distribuciones de las variables aleatorias iniciales que no se cumplen para la distribución especificada (para esta distribución, hay momentos absolutos de todos los órdenes positivos menores que uno, pero la esperanza matemática no existe)... En las obras de O. Koshi, R., que lleva su nombre, apareció en 1853. R. Cauchy está relacionado con X/Y variables aleatorias independientes con R normal estándar.
Entre los más utilizados en la teoría de la probabilidad discreta R. - R. Bernoulli, R. binomial y R. Poisson.
R. Bernoulli es cualquier distribución con dos puntos de crecimiento. La R. más utilizada de una variable aleatoria X tomando valores 0 y 1 con probabilidades
q = 1 - pags y pags respectivamente, donde 0< pags < 1 - параметр. Первые формы закона больших чисел и центральной предельной теоремы были получены для случайных величин, имею-щих Р. Бернулли. Если на вероятностном пространстве (W, Ƒ
, P) hay una secuencia X 1 , X 2, ... variables aleatorias independientes, tomando valores 0 y 1 con probabilidades 1/2 cada uno, entonces en este espacio de probabilidad hay una variable aleatoria con R uniforme en (0, 1). En particular, la variable aleatoria tiene una distribución uniforme en (0, 1).
Binomial R. con parámetros norte y pags, norte- naturales, 0< pags < 1, называется Р., с точками роста 0, 1,..., norte donde se concentran las probabilidades C norte k pag k q norte-k, k = 0, 1,…, norte,
q = 1 - pags... es R. suma norte variables aleatorias independientes con R. Bernoulli con puntos de crecimiento 0 y 1, en las que se concentran las probabilidades q y pags... El estudio de esta distribución llevó a J. Bernoulli al descubrimiento de la ley de los grandes números ya A. Moivre al descubrimiento del teorema del límite central.
Se llama R. de Poisson a una R. cuyo soporte es una secuencia de puntos 0, 1,..., en la que las probabilidades l k e- l / k!, k= 0, 1,…, donde l > 0 es un parámetro. La suma de dos variables aleatorias independientes que tienen R. Poisson con parámetros l y m nuevamente tiene R. Poisson con parámetro l + m. R. Poisson es el límite para R. Bernoulli con parámetros norte y pags = pags(norte) en norte® ¥ si norte y pags relacionados por la razón notario público®l para norte® ¥ (Teorema de Poisson). Si la secuencia es 0< T 1 < T 2 < T 3 <… есть последовательность моментов времени, в которые происходят некоторые события (так. наз поток событий) и величины T 1 , T 2 -T 1 , T 3 - T 2, ... son variables aleatorias independientes distribuidas idénticamente y su P. común es exponencial con parámetro l > 0, entonces la variable aleatoria Xt igual al número de eventos que ocurren en el intervalo (0, t), tiene R. Poisson con parámetro l t(tal flujo se llama Poisson).
El concepto de R. tiene numerosas generalizaciones, en particular, se extiende al caso multidimensional ya las estructuras algebraicas.
La distribución binomial es una de las distribuciones de probabilidad más importantes de una variable aleatoria discretamente variable. La distribución binomial es la distribución de probabilidad del número metro la ocurrencia del evento A v norte observaciones mutuamente independientes... A menudo evento A se llama el "éxito" de la observación, y el evento contrario se llama "fracaso", pero esta designación es muy condicional.
Condiciones de distribución binomial:
- un total de norte juicios en los que el evento A puede o no ocurrir;
- evento A en cada uno de los ensayos puede ocurrir con la misma probabilidad pags;
- las pruebas son mutuamente independientes.
La probabilidad de que en norte evento de prueba A vendrá exactamente metro veces, se puede calcular usando la fórmula de Bernoulli:
![]()
![]() ,
,
donde pags- la probabilidad del evento A;
q = 1 - pags- la probabilidad de que ocurra el evento contrario.
vamos a averiguarlo ¿Por qué la distribución binomial de la manera descrita anteriormente está relacionada con la fórmula de Bernoulli? ... Evento - el número de éxitos con norte Las pruebas se dividen en una serie de opciones, en cada una de las cuales se logra el éxito en metro pruebas y fracasos - en norte - metro pruebas Considere una de esas opciones: B1 ... Usando la regla de la suma de probabilidades, multiplicamos las probabilidades de eventos opuestos:
![]() ,
,
y si denotamos q = 1 - pags, entonces
![]() .
.
Cualquier otra opción tendrá la misma probabilidad en la que metroéxito y norte - metro fallas El número de tales opciones es igual al número de formas en que es posible norte prueba obtener metroéxito.
La suma de las probabilidades de todos metro números de ocurrencia de eventos A(números del 0 al norte) es igual a uno:
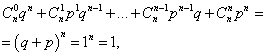
donde cada término es un término en el binomio de Newton. Por lo tanto, la distribución considerada se llama distribución binomial.
En la práctica, a menudo es necesario calcular las probabilidades "no más de metroéxitos en norte prueba "o" al menos metroéxitos en norte pruebas ". Para esto, se utilizan las siguientes fórmulas.
Función integral, es decir probabilidad F(metro) de que en norte evento de observación A no habrá más metro una vez, se puede calcular mediante la fórmula:
En turno probabilidad F(≥metro) de que en norte evento de observación A vendrá al menos metro una vez, se calcula mediante la fórmula:
A veces es más conveniente calcular la probabilidad de que en norte evento de observación A no habrá más metro veces, a través de la probabilidad del evento opuesto:
![]() .
.
Cuál de las fórmulas a usar depende de cuál de ellas la suma contiene menos términos.
Las características de la distribución binomial se calculan mediante las siguientes fórmulas .
Valor esperado: .
Dispersión:.
Desviación Estándar:.
Distribución binomial y cálculos en MS Excel
Probabilidad de distribución binomial PAGS n ( metro) y los valores de la función integral F(metro) se puede calcular usando la función de MS Excel BINOM.DIST. La ventana para el cálculo correspondiente se muestra a continuación (para ampliar, haga clic con el botón izquierdo del mouse).
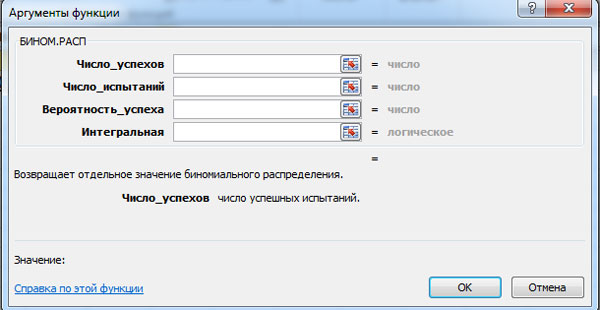
MS Excel requiere que se ingresen los siguientes datos:
- número de éxitos;
- número de pruebas;
- la probabilidad de éxito;
- integral - valor booleano: 0 - si necesita calcular la probabilidad PAGS n ( metro) y 1 - si la probabilidad F(metro).
Ejemplo 1. El gerente de la empresa resumió la información sobre la cantidad de cámaras vendidas en los últimos 100 días. La tabla resume la información y calcula las probabilidades de que se venda una cierta cantidad de cámaras por día.
Un día termina con ganancias si se venden 13 o más cámaras. La probabilidad de que el día se resuelva con una ganancia:
![]()
La probabilidad de que el día se resuelva sin beneficio:
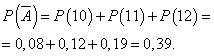
Deje que la probabilidad de que el día se trabaje de manera rentable sea constante e igual a 0,61, y la cantidad de cámaras vendidas por día no depende del día. Entonces puedes usar la distribución binomial, donde el evento A- el día se resolverá con beneficio, - sin beneficio.
La probabilidad de que en 6 días todo se resuelva con una ganancia:
![]() .
.
Obtenemos el mismo resultado usando la función de MS Excel BINOM.DIST (el valor del valor integral es 0):
PAGS 6 (6 ) = DISTR.BINOM.(6; 6; 0,61; 0) = 0,052.
La probabilidad de que de 6 días se trabajen 4 o más días con ganancia:
donde ![]() ,
,
![]() ,
,
Usando la función de MS Excel BINOM.DIST, calculamos la probabilidad de que de 6 días, no más de 3 días se completen con una ganancia (el valor del valor integral es 1):
PAGS 6 (≤3 ) = DISTR.BINOM.(3; 6; 0,61; 1) = 0,435.
La probabilidad de que de 6 días todos sean trabajados con pérdidas:
![]() ,
,
Calculamos el mismo indicador usando la función DISTR.BINOM.DIST de MS Excel:
PAGS 6 (0 ) = DISTR.BINOM.(0; 6; 0,61; 0) = 0,0035.
Resuelva el problema usted mismo y luego vea la solución.
Ejemplo 2. La urna contiene 2 bolas blancas y 3 negras. Saca la bola de la urna, configura el color y vuelve a colocarla. El intento se repite 5 veces. El número de bolas blancas que aparecen es una variable aleatoria discreta X distribuidos de acuerdo con la ley binomial. Elaborar la ley de distribución para una variable aleatoria. Determinar la moda, la expectativa matemática y la varianza.
Seguimos resolviendo problemas juntos
Ejemplo 3. Desde servicio de mensajería fue a los objetos norte= 5 mensajeros. Cada mensajero tiene una probabilidad pags= 0,3, independientemente de los demás, llega tarde al objeto. Variable aleatoria discreta X- el número de correos retrasados. Construya una serie de distribución de esta variable aleatoria. Encuentre su expectativa matemática, varianza, desviación estándar. Encuentre la probabilidad de que al menos dos mensajeros lleguen tarde a los objetos.
A pesar de los nombres exóticos, las distribuciones comunes están relacionadas entre sí de formas muy intuitivas e interesantes que las hacen fáciles de recordar y razonar con confianza. Algunos se siguen naturalmente, por ejemplo, de la distribución de Bernoulli. Es hora de mostrar un mapa de estas conexiones.
Cada distribución se ilustra con un ejemplo de su función de densidad de distribución (PDF). Este artículo trata solo de aquellas distribuciones donde los resultados son números únicos. Por lo tanto, el eje horizontal de cada gráfico es un conjunto de posibles números de resultados. Vertical - la probabilidad de cada resultado. Algunas distribuciones son discretas: sus resultados deben ser números enteros, como 0 o 5. Estos se denotan lineas dispersas, uno para cada resultado, con una altura correspondiente a la probabilidad de este resultado. Algunos son continuos, sus resultados pueden tomar cualquier valor numérico, como -1.32 o 0.005. Estos se muestran mediante curvas densas con áreas debajo de las secciones de la curva que dan probabilidades. La suma de las alturas de las líneas y las áreas bajo las curvas siempre es 1.
Imprime, recorta por la línea punteada y llévalo contigo en la cartera. Esta es su guía para el país de las distribuciones y sus familiares.
Bernoulli y uniforme
Ya te has encontrado con la distribución de Bernoulli arriba, con dos resultados: cara o cruz. Imagínalo ahora como una distribución entre 0 y 1, 0 es cara, 1 es cruz. Como ya está claro, ambos resultados son igualmente probables, y esto se refleja en el diagrama. El SDF de Bernoulli contiene dos líneas de igual altura, que representan 2 resultados igualmente probables: 0 y 1, respectivamente.La distribución de Bernoulli también puede representar resultados desiguales, como lanzar la moneda equivocada. Entonces la probabilidad de cara no será 0,5, sino algún otro valor de p, y la probabilidad de cruz será 1-p. Como muchas otras distribuciones, esta es en realidad una familia completa de distribuciones, dados ciertos parámetros, como p arriba. Cuando pienses en "Bernoulli", piensa en "lanzar una moneda (posiblemente equivocada)".
Este es un paso muy pequeño desde aquí hasta la presentación de la distribución sobre varios resultados equiprobables: una distribución uniforme caracterizada por una SDF plana. Imagina los dados correctos. Sus resultados 1-6 son igualmente probables. Puede especificarse para cualquier número de resultados n, e incluso como una distribución continua.
Piense en la distribución uniforme como el "dado correcto".
Binomial e Hipergeométrica
La distribución binomial se puede considerar como la suma de los resultados de aquellas cosas que siguen la distribución de Bernoulli.Lance una moneda honesta dos veces: ¿cuántas veces habrá cara? Este es un número de distribución binomial. Sus parámetros son n, el número de intentos, y p es la probabilidad de "éxito" (en nuestro caso, cara o 1). Cada tirada es un resultado o prueba distribuido por Bernoulli. Usa la distribución binomial cuando cuentes los éxitos en cosas como el lanzamiento de una moneda, donde cada lanzamiento es independiente de los demás y tiene la misma probabilidad de éxito.
O imagina una urna con el mismo número de bolas blancas y negras. Cierra los ojos, saca la pelota, escribe su color y vuelve a colocarla. Repetir. ¿Cuántas veces ha salido la bola negra? Este número también obedece a la distribución binomial.
Presentamos esta extraña situación para facilitar la comprensión del significado de la distribución hipergeométrica. Esta es la distribución del mismo número, pero en una situación si no devolvió las pelotas. Ciertamente es prima de la distribución binomial, pero no la misma, ya que la probabilidad de éxito cambia con cada bola extraída. Si el número de bolas es lo suficientemente grande en comparación con el número de tiros, entonces estas distribuciones son prácticamente las mismas, ya que la probabilidad de éxito cambia muy poco con cada tiro.
Cuando hablan en alguna parte de sacar bolas de urnas sin devolverlas, casi siempre es seguro decir "sí, distribución hipergeométrica", porque nunca en mi vida he conocido a nadie que realmente llene urnas con bolas y luego las saque y las devuelva. , o viceversa. Ni siquiera tengo conocidos con urnas. Aún más a menudo, esta distribución debería surgir al elegir un subconjunto significativo de alguna población general como muestra.
Aprox. traducir
Puede que no quede muy claro aquí, y dado que hay un tutorial y un curso express para principiantes, conviene aclararlo. La población general es algo que queremos medir estadísticamente. Para la evaluación, elegimos una determinada parte (subconjunto) y hacemos la estimación requerida sobre ella (entonces este subconjunto se denomina muestra), asumiendo que la estimación será similar para toda la población. Pero para que esto sea cierto, a menudo se requieren restricciones adicionales en la definición de un subconjunto de la muestra (o viceversa, a partir de una muestra conocida, necesitamos evaluar si describe a la población con suficiente precisión).
Un ejemplo práctico: necesitamos seleccionar representantes de una empresa de 100 personas para viajar al E3. Se sabe que ya han viajado 10 personas en él el año pasado (pero nadie lo admite). ¿Cuánto es lo mínimo que debe tomar para que haya una alta probabilidad de que haya al menos un compañero experimentado en el grupo? En este caso, la población general es 100, la muestra es 10 y los requisitos de la muestra son al menos uno que ya haya viajado a E3.
Wikipedia tiene un ejemplo menos divertido pero más práctico sobre piezas defectuosas en un lote.
veneno
¿Qué pasa con la cantidad de clientes que llaman a la línea directa de soporte técnico cada minuto? Este es un resultado cuya distribución es binomial a primera vista, si contamos cada segundo como una prueba de Bernoulli, durante el cual el cliente o no llama (0) o llama (1). Pero las organizaciones de suministro de energía lo saben muy bien: cuando cortan la electricidad, dos personas pueden llamar en un segundo. o incluso más de cien personas. Presentar esto como 60,000 pruebas de milisegundos tampoco ayudará: hay más pruebas, la probabilidad de que suene en un milisegundo es menor, incluso si no tiene en cuenta dos o más al mismo tiempo, pero, técnicamente, esto sigue siendo no es una prueba de Bernoulli. Sin embargo, el razonamiento lógico con la transición al infinito funciona. Sea n tiende a infinito, yp - a 0, y de modo que np es constante. Es como dividir en fracciones cada vez más pequeñas el tiempo con cada vez menos probabilidad de una llamada. En el límite, obtenemos la distribución de Poisson.Al igual que la binomial, la distribución de Poisson es una distribución de cantidad: el número de veces que sucede algo. No está parametrizado por la probabilidad p y el número de intentos n, sino por la intensidad media λ, que, por analogía con el binomio, es simplemente un valor constante de np. La distribución de Poisson es lo que necesario recuerda cuando se trata de contar eventos durante un tiempo determinado a una intensidad dada constante.
Cuando hay algo como un paquete que llega a un enrutador o un cliente en una tienda o algo esperando en la fila, piense en Poisson.
Binomio geométrico y negativo
Una distribución diferente surge de las pruebas simples de Bernoulli. ¿Cuántas veces sale cruz una moneda antes de salir cara? El número de cruces sigue una distribución geométrica. Al igual que la distribución de Bernoulli, está parametrizada por la probabilidad de un resultado exitoso, p. No está parametrizado por el número n, el número de tiradas de prueba, porque el número de pruebas fallidas es exactamente el resultado.Si la distribución binomial es "¿cuántos éxitos?", entonces la distribución geométrica es "¿cuántos fracasos antes del éxito?"
La distribución binomial negativa es una simple generalización de la anterior. Este es el número de fallas antes de r, no 1, éxitos. Por lo tanto, está parametrizado adicionalmente por este r. A veces se describe como el número de éxitos de r fracasos. Pero, como dice mi entrenador de vida: “Tú mismo decides qué es el éxito y qué es el fracaso”, entonces esto es lo mismo, si no olvidas que la probabilidad p también debe ser la probabilidad correcta de éxito o fracaso, respectivamente.
Si necesita una broma para aliviar el estrés, puede mencionar que las distribuciones binomial e hipergeométrica son un par obvio, pero los binomios geométricos y negativos también son muy similares, y luego decir "Bueno, ¿quién los llama así, eh?"
Exponencial y Weibula
Nuevamente sobre las llamadas al soporte técnico: ¿cuánto tiempo pasará hasta la próxima llamada? La distribución de este tiempo de espera parece ser geométrica, porque cada segundo, mientras nadie llama, es como un fracaso, hasta un segundo, hasta que finalmente se realiza la llamada. La cantidad de fallas es como la cantidad de segundos hasta que nadie llama, y esto prácticamente tiempo hasta la próxima convocatoria, pero "prácticamente" no nos alcanza. La conclusión es que este tiempo será la suma de segundos enteros y, por lo tanto, no será posible contar la espera dentro de este segundo antes de la llamada en sí.Bueno, como antes, pasamos la distribución geométrica al límite, en relación con los tiempos compartidos, y listo. Obtenemos una distribución exponencial que describe con precisión el tiempo antes de la llamada. Esta es una distribución continua, la primera es la nuestra, porque el resultado no es necesariamente en segundos enteros. Al igual que la distribución de Poisson, está parametrizada por la intensidad λ.
Repitiendo la conexión entre el binomio y lo geométrico, el "¿cuántos eventos en el tiempo?" de Poisson está relacionado con el exponencial "¿cuánto antes del evento?" Si hay eventos, cuyo número por unidad de tiempo obedece a la distribución de Poisson, entonces el tiempo entre ellos obedece a una distribución exponencial con el mismo parámetro λ. Esta correspondencia entre las dos distribuciones debe notarse cuando se discute cualquiera de ellas.
Debería pensarse en una distribución exponencial cuando se piensa en "tiempo hasta el evento", tal vez "tiempo hasta el fallo". De hecho, esta es una situación tan importante que existen distribuciones más generalizadas para describir el MTBF, como la distribución de Weibull. Si bien la distribución exponencial es apropiada cuando la tasa (de desgaste o falla, por ejemplo) es constante, la distribución de Weibull puede simular la tasa creciente (o decreciente) de fallas a lo largo del tiempo. La exponencial es, en general, un caso especial.
Piense en Weibul cuando se trata de MTBF.
Normal, Lognormal, Student y Chi-cuadrado
La distribución normal o gaussiana es probablemente una de las más importantes. Su forma en forma de campana es inmediatamente reconocible. Además, es una entidad particularmente curiosa que se manifiesta en todas partes, incluso desde las fuentes aparentemente más simples. Tome un conjunto de valores que obedezcan una distribución, ¡cualquiera! - y doblarlos. La distribución de su suma obedece (aproximadamente) a una distribución normal. Cuantas más cosas se suman, más se acerca su suma a la distribución normal (objetivo: la distribución de los términos debe ser predecible, ser independiente, tiende solo a la normal). Que este sea el caso a pesar de la distribución original es increíble.Aprox. traducir
Me sorprendió que el autor no escriba sobre la necesidad de una escala comparable de las distribuciones sumadas: si una domina esencialmente a las demás, será extremadamente malo que converjan. Y, en general, la absoluta independencia mutua es opcional, la dependencia débil es suficiente.
Bueno, probablemente sirva para fiestas, como escribió.
Esto se llama el "teorema del límite central", y necesitas saber qué es, por qué se llama así y qué significa, de lo contrario, se reirán al instante.
En su contexto, la normal está asociada con todas las distribuciones. Aunque, por lo general, se asocia a los repartos de cualquier cantidad. La suma de los ensayos de Bernoulli sigue la distribución binomial y, a medida que aumenta el número de ensayos, esta distribución binomial se acerca cada vez más a la distribución normal. Del mismo modo, su prima, la distribución hipergeométrica. La distribución de Poisson, la forma límite de la binomial, también se acerca a la normal con un aumento en el parámetro de intensidad.
Los resultados que obedecen a una distribución lognormal dan valores cuyo logaritmo se distribuye normalmente. O en otras palabras: el exponente de un valor normalmente distribuido tiene una distribución lognormal. Si las sumas se distribuyen normalmente, recuerde también que los productos se distribuyen lognormalmente.
La distribución t de Student es el corazón de la prueba t que muchos no estadísticos estudian en otros campos. Se utiliza para hacer suposiciones sobre la media de una distribución normal y también tiende a una distribución normal con un aumento en su parámetro. Una característica distintiva de la distribución t son sus colas, que son más gruesas que las de la distribución normal.
Si la anécdota de la cola gorda no sacudió lo suficiente a su vecino, vaya a un cuento bastante divertido sobre la cerveza. Hace más de 100 años, Guinness usó estadísticas para mejorar su cerveza negra. Fue entonces cuando William Seeley Gosset inventó una teoría estadística completamente nueva para mejorar la producción de cebada. Gossett convenció a su jefe de que otros cerveceros no entenderían cómo usar sus ideas y recibió permiso para publicar, pero bajo el seudónimo de "Estudiante". El logro más famoso de Gosset es esta misma distribución t, que, se podría decir, lleva su nombre.
Finalmente, la distribución chi-cuadrado es la distribución de las sumas de cuadrados de cantidades normalmente distribuidas. La prueba de chi-cuadrado se basa en esta distribución, que a su vez se basa en la suma de los cuadrados de las diferencias, que deberían tener una distribución normal.
gamma y beta
En este punto, si ya ha comenzado a hablar sobre algo de chi-cuadrado, la conversación comienza en serio. Es posible que ya esté hablando con estadísticos reales, y podría valer la pena hacer una reverencia, ya que podrían surgir cosas como la distribución gamma. Esta generalización y exponencial, y distribución chi-cuadrado. Al igual que la distribución exponencial, se utiliza para modelos de latencia complejos. Por ejemplo, la distribución gamma aparece cuando se simula el tiempo hasta los próximos n eventos. Aparece en el aprendizaje automático como una "distribución previa conjugada" a un par de otras distribuciones.No entre en la conversación sobre estas distribuciones conjugadas, pero si es necesario, no olvide mencionar la distribución beta, porque es la conjugada anterior a la mayoría de las distribuciones mencionadas aquí. Los científicos de datos confían en que esto es exactamente para lo que fue creado. Menciona esto sin darte cuenta y ve a la puerta.
El comienzo de la sabiduría.
Las distribuciones de probabilidad son algo sobre lo que no se puede saber demasiado. Aquellos verdaderamente interesados pueden consultar este mapa súper detallado de todas las distribuciones de probabilidad. ¿Cuál es la idea del razonamiento probabilístico?El primer paso, el más natural en el razonamiento probabilístico, es el siguiente: si tienes una variable que toma valores al azar, entonces te gustaría saber con qué probabilidades esa variable toma ciertos valores. La combinación de estas probabilidades es precisamente lo que determina la distribución de probabilidad. Por ejemplo, con un dado, puedes a priori suponer que con iguales probabilidades 1/6 caerá sobre cualquier arista. Y esto sucede bajo la condición de que el hueso sea simétrico. Si el hueso es asimétrico, entonces es posible determinar altas probabilidades para aquellas caras que se caen con mayor frecuencia y menores probabilidades para aquellas caras que se caen con menos frecuencia, según los datos experimentales. Si alguna arista no cae en absoluto, entonces se le puede asignar una probabilidad de 0. Esta es la ley de probabilidad más simple que se puede usar para describir los resultados de lanzar un dado. Por supuesto, este es un ejemplo extremadamente simple, pero surgen problemas similares, por ejemplo, en los cálculos actuariales, cuando el riesgo real se calcula en base a datos reales al emitir una póliza de seguro.
En este capítulo, veremos las leyes probabilísticas más comunes en la práctica.
Estas distribuciones se pueden trazar fácilmente en STATISTICA.
Distribución normal
La distribución de probabilidad normal se usa especialmente en estadística. La distribución normal da buen modelo para fenómenos reales en los que:
1) existe una fuerte tendencia a que los datos se agrupen alrededor de un centro;
2) positivo y desviaciones negativas equiprobable desde el centro;
3) la frecuencia de las desviaciones disminuye rápidamente cuando las desviaciones del centro se vuelven grandes.
El mecanismo que subyace a la distribución normal, explicado utilizando el llamado teorema del límite central, se puede describir en sentido figurado de la siguiente manera. Imagina que tienes partículas de polen que arrojaste al azar en un vaso de agua. Mirando una partícula individual bajo un microscopio, verá un fenómeno sorprendente: la partícula se está moviendo. Por supuesto, esto sucede porque las moléculas de agua se mueven y transfieren su movimiento a las partículas de polen en suspensión.
Pero, ¿cómo se produce exactamente el movimiento? Aquí hay una pregunta más interesante. ¡Y este movimiento es muy extraño!
Hay un número infinito de influencias independientes en una partícula de polen individual en forma de impactos de moléculas de agua, que hacen que la partícula se mueva a lo largo de una trayectoria muy extraña. Bajo el microscopio, este movimiento se asemeja a una línea rota repetida y caóticamente. Estas torceduras no se pueden predecir, no hay regularidad en ellas, lo que corresponde exactamente a las caóticas colisiones de moléculas en una partícula. Una partícula suspendida, después de haber experimentado el impacto de una molécula de agua en un momento aleatorio, cambia su dirección de movimiento, luego se mueve por algún tiempo por inercia, luego vuelve a caer bajo el impacto de la siguiente molécula, y así sucesivamente. ¡Hay una mesa de billar increíble en un vaso de agua!
Dado que el movimiento de las moléculas tiene una dirección y una velocidad aleatorias, la magnitud y la dirección de las torceduras en la trayectoria también son completamente aleatorias e impredecibles. Este asombroso fenómeno, llamado movimiento browniano, descubierto en el siglo XIX, nos hace pensar en muchas cosas.
Si introducimos un sistema adecuado y marcamos las coordenadas de la partícula en unos instantes de tiempo, entonces obtendremos la ley normal. Más precisamente, los desplazamientos de la partícula de polen derivados del impacto de las moléculas obedecerán a la ley normal.
Por primera vez, la ley de movimiento de tal partícula, llamada browniana, fue descrita en el nivel físico de rigor por A. Einstein. Entonces Lenjevan desarrolló un enfoque más simple e intuitivo.
Los matemáticos del siglo XX dedicaron sus mejores páginas a esta teoría, y el primer paso se dio hace 300 años, cuando se descubrió la versión más sencilla del teorema del límite central.
En la teoría de la probabilidad, el teorema del límite central, originalmente conocido en la formulación de Moivre y Laplace ya en el siglo XVII como un desarrollo de la famosa ley de los grandes números de J. Bernoulli (1654-1705) (ver J. Bernoulli (1713) ), Ars Conjectandi), ahora está extremadamente desarrollado y alcanzó su punto máximo. en el principio moderno de invariancia, en cuya creación la escuela matemática rusa desempeñó un papel esencial. Es en este principio que el movimiento de una partícula browniana encuentra su explicación matemática rigurosa.
La idea es que al sumar un gran número de cantidades independientes (impactos de moléculas sobre partículas de polen) bajo ciertas condiciones razonables, son precisamente las cantidades normalmente distribuidas las que se obtienen. Y esto sucede independientemente, es decir, invariablemente, de la distribución de los valores iniciales. En otras palabras, si una variable está influenciada por muchos factores, estas influencias son independientes, relativamente pequeñas y se suman entre sí, entonces el valor resultante tiene una distribución normal.
Por ejemplo, una cantidad casi infinita de factores determinan el peso de una persona (miles de genes, predisposición, enfermedades, etc.). Por lo tanto, se puede esperar una distribución normal del peso en la población de todas las personas.
Si usted es un financiero y juega en la bolsa de valores, entonces, por supuesto, está al tanto de los casos en que los precios de las acciones se comportan como partículas brownianas, experimentando impactos caóticos de muchos factores.

Formalmente, la densidad de la distribución normal se escribe de la siguiente manera:

donde a y x 2 son los parámetros de la ley, interpretados, respectivamente, como el valor medio y la varianza de una variable aleatoria dada (debido al rol especial de la distribución normal, usaremos una notación especial para denotar su función de densidad y distribución función). Visualmente, el gráfico de densidad normal es la famosa curva en forma de campana.
La función de distribución correspondiente de la variable aleatoria normal (a, x 2) se denota por Ф (x; a, x 2) y viene dada por la relación:

Una ley normal con parámetros a = 0 y x 2 = 1 se llama estándar.
Función de distribución normal estándar inversa aplicada a z, 0 Utilice la calculadora probabilística STATISTICA para calcular z a partir de x y viceversa. Características básicas de la ley normal: Promedio, moda, mediana: E = x mod = x med = a; Dispersión: D = х 2; Asimetría: Exceso: Se puede ver a partir de las fórmulas que la distribución normal se describe mediante dos parámetros: a - media - promedio; õ - desviación estándar - desviación estándar, léase: "sigma". A veces con la desviación estándar se llama desviación estándar, pero esta ya es una terminología obsoleta. Aquí hay algunos datos útiles sobre la distribución normal. La media determina la medida de la distribución de densidad. La densidad de distribución normal es simétrica con respecto a la media. La media de la distribución normal coincide con la mediana y la moda (ver gráficos). Densidad de distribución normal con varianza 1 y media 1 Densidad de distribución normal con media 0 y varianza 0.01 Densidad de distribución normal con media 0 y varianza 4 Con un aumento en la varianza, la densidad de la distribución normal se extiende o se extiende a lo largo del eje OX; con una disminución en la varianza, por el contrario, se contrae, concentrándose alrededor de un punto: el punto de valor máximo que coincide con la media valor. En el caso límite de varianza cero, la variable aleatoria degenera y toma un único valor igual a la media. Es útil conocer las reglas de 2 y 3 sigma, o de 2 y 3 desviaciones estándar, que están asociadas con la distribución normal y se utilizan en una variedad de aplicaciones. El significado de estas reglas es muy simple. Si se establecen dos y tres desviaciones estándar (2 y 3 sigma) a la derecha y a la izquierda, respectivamente, del punto medio o, lo que es lo mismo, del punto de máxima densidad de la distribución normal, entonces el área bajo el gráfico de densidad normal calculado sobre este intervalo será, respectivamente, igual al 95,45 % y al 99,73 % de toda el área bajo el gráfico (verifique en la calculadora probabilística STATISTICA!). En otras palabras, esto se puede expresar de la siguiente manera: el 95,45 % y el 99,73 % de todas las observaciones independientes de la población normal, por ejemplo, el tamaño de una pieza o el precio de las acciones, se encuentran en la zona de 2 y 3 desviaciones estándar. de la media. Distribución equitativa La distribución uniforme es útil cuando se describen variables en las que cada valor es igualmente probable, en otras palabras, los valores de una variable se distribuyen uniformemente en alguna área. A continuación se muestran las fórmulas de densidad y las funciones de distribución de una variable aleatoria uniforme que toma valores en el intervalo [a, b]. De estas fórmulas es fácil entender que la probabilidad de que una variable aleatoria uniforme tome valores del conjunto [c, d] [a, b] es igual a (d - c) / (b - a). Nosotros ponemos a = 0, b = 1. A continuación se muestra un gráfico de una densidad de probabilidad uniforme centrada en un segmento. Características numéricas de la ley uniforme: Distribución exponencial Hay eventos que pueden llamarse raros en el lenguaje ordinario. Si T es el tiempo entre el inicio de eventos raros que ocurren en promedio con una intensidad X, entonces el valor Esta distribución tiene una propiedad muy interesante de ausencia de efecto secundario, o, como se dice, la propiedad de Markov, en honor al famoso matemático ruso A.A. Markov, que se puede explicar de la siguiente manera. Si la distribución entre los momentos de ocurrencia de algunos eventos es indicativa, entonces la distribución contada desde cualquier momento t hasta el próximo evento también tiene una distribución exponencial (con el mismo parámetro). En otras palabras, para un flujo de eventos raros, el tiempo de espera para el próximo visitante siempre se distribuye exponencialmente, independientemente de cuánto tiempo lo haya estado esperando. La distribución exponencial está asociada con la distribución de Poisson: en una unidad de intervalo de tiempo, el número de eventos, cuyos intervalos son independientes y están distribuidos exponencialmente, tiene una distribución de Poisson. Si los intervalos entre las visitas al sitio tienen una distribución exponencial, entonces el número de visitas, por ejemplo, dentro de una hora, se distribuye de acuerdo con la ley de Poisson. La distribución exponencial es un caso especial de la distribución de Weibull. Si el tiempo no es continuo, sino discreto, entonces el análogo de la distribución exponencial es la distribución geométrica. La densidad de distribución exponencial se describe mediante la fórmula: Esta distribución tiene un solo parámetro, que determina sus características. El gráfico de densidad de distribución exponencial tiene la forma: Características numéricas básicas de la distribución exponencial: Distribución Erlang Esta distribución continua está centrada en (0,1) y tiene una densidad: La expectativa matemática y la varianza son iguales respectivamente La distribución de Erlang lleva el nombre de A. Erlang, quien la aplicó por primera vez a problemas en la teoría de colas y telefonía. La distribución de Erlang con parámetros µ y n es la distribución de la suma de n variables aleatorias independientes idénticamente distribuidas, cada una de las cuales tiene una distribución exponencial con el parámetro nµ En La distribución Erlang n = 1 es la misma que la distribución exponencial o exponencial. Distribución de Laplace La función de densidad de la distribución de Laplace, o, como también se le llama, doble exponencial, se utiliza, por ejemplo, para describir la distribución de errores en los modelos de regresión. Si observa el gráfico de esta distribución, verá que consta de dos distribuciones exponenciales, simétricas con respecto al eje OY. Si el parámetro de posición es 0, entonces la función de densidad de distribución de Laplace tiene la forma: Las principales características numéricas de esta ley de distribución, asumiendo que el parámetro de posición es cero, son las siguientes: En el caso general, la densidad de distribución de Laplace tiene la forma: a es la media de la distribución; b es el parámetro de escala; e es el número de Euler (2,71...). Distribución gamma La densidad de distribución exponencial tiene una moda en el punto 0, y esto a veces es un inconveniente para las aplicaciones prácticas. En muchos ejemplos, se sabe de antemano que la moda de la variable aleatoria considerada no es igual a 0, por ejemplo, los intervalos entre los compradores que llegan a una tienda de comercio electrónico o visitan un sitio tienen una moda pronunciada. La distribución gamma se utiliza para simular tales eventos. La densidad de la distribución gamma es la siguiente: donde Γ es la función Γ de Euler, a> 0 es el parámetro de "forma" y b> 0 es el parámetro de escala. En un caso particular, tenemos una distribución Erlang y una distribución exponencial. Las principales características de la distribución gamma: A continuación se muestran dos gráficos de densidad gamma con un parámetro de escala de 1 y parámetros de forma de 3 y 5. Una propiedad útil de la distribución gamma: la suma de cualquier número de variables aleatorias distribuidas gamma independientes (con el mismo parámetro de escala b) (a l, b) + (a 2, b) + --- + (a n, b) también obedece a la distribución gamma, pero con los parámetros a 1 + a 2 + + a n y b. Distribución lognormal Una variable aleatoria h se llama log-normal o log-normal, si su logaritmo natural (lnh) obedece la ley de distribución normal. La distribución lognormal se usa, por ejemplo, cuando se modelan variables como ingresos, edad de los recién casados o tolerancia de la norma de sustancias nocivas en los alimentos. Entonces, si la cantidad x tiene una distribución normal, entonces la cantidad y = e x tiene una distribución Lognormal. Si sustituye el valor normal en la potencia exponencial, comprenderá fácilmente que el valor lognormal se obtiene como resultado de múltiples multiplicaciones de valores independientes, al igual que una variable aleatoria normal es el resultado de una suma múltiple. La densidad de la distribución lognormal es: Las principales características de una distribución lognormal son: Distribución chi-cuadrado La suma de cuadrados de m valores normales independientes con media 0 y varianza 1 tiene una distribución chi-cuadrado con m grados de libertad. Esta distribución se usa más comúnmente en el análisis de datos. Formalmente, la densidad de la distribución cuadrática con m grados de libertad tiene la forma: con negativo x densidad se convierte en 0. Características numéricas básicas de la distribución chi-cuadrado: El diagrama de densidad se muestra en la siguiente figura: Distribución binomial La distribución binomial es la distribución discreta más importante que se concentra en unos pocos puntos. La distribución binomial asigna probabilidades positivas a estos puntos. Así, la distribución binomial difiere de las distribuciones continuas (normal, chi-cuadrado, etc.), que asignan probabilidades cero a puntos seleccionados por separado y se denominan continuas. Puedes entender mejor la distribución binomial observando el siguiente juego. Imagina que estás lanzando una moneda. Sea la probabilidad de que se caiga el escudo de armas p, y la probabilidad de obtener cruz es q = 1 - p (consideramos el caso más general cuando la moneda es asimétrica, tiene, por ejemplo, un centro de gravedad desplazado: se hace un agujero en la moneda). La caída del escudo de armas se considera un éxito, y la caída de las colas se considera un fracaso. Entonces, el número de escudos de armas (o colas) caídos tiene una distribución binomial. Tenga en cuenta que la consideración de monedas asimétricas o dados irregulares es de interés práctico. Como señaló J. Neumann en su elegante libro "Un curso de introducción a la teoría de la probabilidad y la estadística matemática", la gente ha adivinado durante mucho tiempo que la frecuencia de los puntos que caen en un dado depende de las propiedades de este dado y puede cambiarse artificialmente. Los arqueólogos encontraron dos pares de huesos en la tumba del faraón: "honestos", con las mismas probabilidades de que todos los lados se caigan, y falsos, con un cambio deliberado del centro de gravedad, lo que aumentó la probabilidad de que se caigan los seis. Los parámetros de la distribución binomial son la probabilidad de éxito p (q = 1 - p) y el número de pruebas n. La distribución binomial es útil para describir la distribución de eventos binomiales, como el número de hombres y mujeres en empresas seleccionadas al azar. El uso de la distribución binomial en problemas de juegos es de particular importancia. La fórmula exacta para la probabilidad t de éxitos en n pruebas se escriben de la siguiente manera: p-probabilidad de éxito q es igual a 1-p, q> = 0, p + q == 1 n- número de pruebas, m = 0.1 ... m Las principales características de la distribución binomial: La gráfica de esta distribución para un número diferente de intentos n y probabilidades de éxito p tiene la forma: La distribución binomial está relacionada con la distribución normal y la distribución de Poisson (ver más abajo); a ciertos valores de los parámetros en un número grande pruebas se convierte en estas distribuciones. Esto se demuestra fácilmente con STATISTICA. Por ejemplo, considerando la gráfica de la distribución binomial con parámetros p = 0.7, n = 100 (ver figura), usamos STATISTICA BASIC - puedes notar que el gráfico es muy similar a la densidad de la distribución normal (¡realmente lo es!). Gráfica de distribución binomial con parámetros p = 0,05, n = 100 es muy similar a la gráfica de la distribución de Poisson. Como ya se mencionó, la distribución binomial surgió de las observaciones del juego de apuestas más simple: lanzar la moneda correcta. En muchas situaciones, este modelo sirve bueno primero aproximación para juegos más complejos y procesos aleatorios que surgen al jugar en la bolsa de valores. Es notable que las características esenciales de muchos procesos complejos puedan entenderse a partir de un modelo binomial simple. Por ejemplo, considere la siguiente situación. Marquemos la caída del escudo de armas como 1, y la caída de las colas - menos 1, y resumiremos las ganancias y pérdidas en los sucesivos momentos del tiempo. Los gráficos muestran las trayectorias típicas de un juego de este tipo con 1000 lanzamientos, 5000 lanzamientos y 10 000 lanzamientos. Preste atención a cuánto tiempo la trayectoria está por encima o por debajo de cero, en otras palabras, el tiempo durante el cual uno de los jugadores está ganando en un juego absolutamente justo es muy largo, y las transiciones de ganar a perder son relativamente raras, y esto es difícil de encajar en una mente no preparada, para quien la expresión "juego absolutamente limpio" suena como un hechizo mágico. Entonces, aunque el juego es justo bajo las condiciones, ¡el comportamiento de una trayectoria típica no es justo en absoluto y no muestra equilibrio! Por supuesto, empíricamente este hecho es conocido por todos los jugadores, se le asocia una estrategia, cuando al jugador no se le permite irse con una victoria, sino que se ve obligado a seguir jugando. Considere el número de lanzamientos durante los cuales un jugador gana (trayectoria por encima de 0) y el otro pierde (trayectoria por debajo de 0). A primera vista, parece que el número de tales lanzamientos es casi el mismo. Sin embargo (ver el libro fascinante: Feller V. "Introducción a la teoría de la probabilidad y sus aplicaciones". Moscú: Mir, 1984, p. 106) con 10,000 lanzamientos de una moneda ideal p = q = 0,5, n = 10.000) la probabilidad de que una de las partes lidere durante más de 9.930 juicios y la otra, menos de 70, supera el 0,1. Sorprendentemente, en un juego de 10.000 lanzamientos de la moneda correcta, la probabilidad de un cambio de liderazgo de no más de 8 veces es mayor a 0,14, y la probabilidad de más de 78 cambios de liderazgo es de aproximadamente 0,12. Entonces, tenemos una situación paradójica: en la caminata simétrica de Bernoulli, las "ondas" en el gráfico entre retornos cero sucesivos (ver gráficos) pueden ser sorprendentemente largas. Esto está relacionado con otra circunstancia, a saber, que para T n/n (la fracción de tiempo en que el gráfico está por encima del eje de abscisas) los valores menos probables están cerca de 1/2. Los matemáticos descubrieron la llamada ley del arcoseno, según la cual para cada 0< а <1 вероятность неравенства
, где Т n - число шагов, в течение которых первый игрок находится в выигрыше, стремится к distribución arcoseno Esta distribución continua se concentra en el intervalo (0, 1) y tiene una densidad: La distribución del seno inverso está asociada con un paseo aleatorio. Esta es la distribución de la proporción de tiempo durante el cual el primer jugador está ganando al lanzar una moneda simétrica, es decir, una moneda que con las mismas probabilidades S cae en escudo de armas y colas. De otra manera, tal juego puede verse como un paseo aleatorio de una partícula que, comenzando desde cero, hace saltos unitarios hacia la derecha o hacia la izquierda con iguales probabilidades. Dado que los saltos de la partícula, la apariencia del escudo de armas o la cola, son igualmente probables, tal caminata a menudo se denomina simétrica. Si las probabilidades fueran diferentes, entonces tendríamos una caminata asimétrica. El gráfico de la densidad de distribución del arcoseno se muestra en la siguiente figura: Lo más interesante es la interpretación de alta calidad del gráfico, del cual puedes sacar conclusiones sorprendentes sobre la racha ganadora y la racha perdedora en un juego limpio. Mirando el gráfico, puede ver que el mínimo de densidad está en el punto 1/2 "¡¿Y qué?!" - usted pregunta. Pero si piensas en esta observación, ¡entonces no habrá límites para tu sorpresa! Resulta que cuando se define como justo, el juego en realidad no es tan justo como podría parecer a primera vista. Las trayectorias de un azar simétrico, en las que una partícula pasa el mismo tiempo en los semiejes positivo y negativo, es decir, a la derecha o a la izquierda de cero, son las menos probables. Pasando al lenguaje de los jugadores, podemos decir que al lanzar una moneda simétrica, los juegos en los que los jugadores están igual de tiempo ganando y perdiendo son los menos probables. Por el contrario, los juegos en los que un jugador tiene muchas más probabilidades de ganar y el otro, respectivamente, de perder, son los más probables. ¡Una paradoja asombrosa! Para calcular la probabilidad de que la fracción de tiempo t durante la cual gane el primer jugador esté en el rango de t1 a t2, es necesario a partir del valor de la función de distribución F (t2) resta el valor de la función de distribución F (t1). Formalmente obtenemos: P(t1 Con base en este hecho, es posible calcular usando STATISTICA que a los 10.000 pasos la partícula permanece en el lado positivo de más de 9930 instantes de tiempo con una probabilidad de 0.1, es decir, en términos generales, tal situación se observará al menos en un caso de cada diez (aunque, a primera vista, parece absurdo; ver la nota notablemente clara de Yu. V. Prokhorov "Bernoulli's Walk" en la enciclopedia "Probability and Mathematical Statistics", pp. 42-43, Moscú: Gran Enciclopedia Rusa, 1999) ... Distribución binomial negativa Esta es una distribución discreta que asigna a los puntos enteros k = 0,1,2, ... probabilidades: p k = P (X = k) = C k r + k-1 p r (l-p) k ", donde 0<р<1,r>0.
La distribución binomial negativa se encuentra en muchas aplicaciones. En general r> 0 distribución binomial negativa se interpreta como la distribución del tiempo de espera para el r-ésimo "éxito" en el esquema de prueba de Bernoulli con la probabilidad de "éxito" p, por ejemplo, el número de rollos que se deben hacer antes de que se lance el segundo escudo de armas, en cuyo caso a veces se le llama distribución Pascal y es un análogo discreto de la distribución gamma. En r = 1 distribución binomial negativa coincide con distribución geométrica. Si Y es una variable aleatoria con distribución de Poisson con un parámetro aleatorio, que a su vez tiene una distribución gamma con densidad Entonces Ub tendrá una distribución binomial negativa con parámetros; distribución de veneno La distribución de Poisson a veces se denomina distribución de eventos raros. Ejemplos de variables distribuidas según la ley de Poisson son: el número de accidentes, el número de defectos en el proceso de fabricación, etc. La distribución de Poisson viene determinada por la fórmula: Las principales características de una variable aleatoria de Poisson: La distribución de Poisson está relacionada con la distribución exponencial y la distribución de Bernoulli. Si el número de eventos tiene una distribución de Poisson, entonces los intervalos entre eventos tienen una distribución exponencial o exponencial. Diagrama de distribución de Poisson: Compare el gráfico de la distribución de Poisson con el parámetro 5 con el gráfico de la distribución de Bernoulli en p = q = 0,5, n = 100. Verás que las gráficas son muy parecidas. En el caso general, existe el siguiente patrón (ver, por ejemplo, el excelente libro: Shiryaev AN "Probabilidad". Moscú: Nauka, p. 76): si en las pruebas de Bernoulli n toma valores grandes, y la probabilidad de éxito / ? es relativamente pequeño, por lo que el número promedio de éxitos (producto y siesta) no es pequeño ni grande, entonces la distribución de Bernoulli con parámetros n, p puede ser reemplazada por la distribución de Poisson con parámetro = np. La distribución de Poisson se usa ampliamente en la práctica, por ejemplo, en gráficos de control de calidad como una distribución de eventos raros. Como otro ejemplo, considere el siguiente problema relacionado con líneas telefónicas y tomado de la práctica (ver: Feller V. Introducción a la teoría de la probabilidad y sus aplicaciones. Moscú: Mir, 1984, p. 205, y también Molina E. S. (1935) Probabilidad en ingeniería, Ingeniería eléctrica, 54, páginas 423-427;Monografía B-854 de publicaciones técnicas de Bell Telephone System). Esta tarea es fácil de traducir a un lenguaje moderno, por ejemplo, al lenguaje de las comunicaciones móviles, que es a lo que se invita a los lectores interesados. El problema se formula de la siguiente manera. Sean dos centrales telefónicas: A y B. La central telefónica A debe garantizar la comunicación de 2.000 abonados con la central B. La calidad de la comunicación debe ser tal que sólo 1 llamada de cada 100 espere a que la línea quede libre. La pregunta es: ¿cuántas líneas telefónicas necesita instalar para garantizar la calidad de comunicación dada? Obviamente, es una tontería crear 2.000 líneas, ya que muchas de ellas serán gratuitas durante mucho tiempo. A partir de consideraciones intuitivas, está claro que, aparentemente, existe un número óptimo de líneas N. ¿Cómo calcular este número? Comencemos con un modelo realista que describa la intensidad del acceso del suscriptor a la red, y tenga en cuenta que la precisión del modelo puede, por supuesto, verificarse utilizando criterios estadísticos estándar. Entonces, supongamos que cada suscriptor usa la línea en promedio 2 minutos por hora y las conexiones de los suscriptores son independientes (sin embargo, como bien lo señala Feller, esto último ocurre si no hay eventos que afecten a todos los suscriptores, por ejemplo, una guerra o una huracán). Luego tenemos 2000 pruebas de Bernoulli (lanzamiento de una moneda) o conexiones de red con una tasa de éxito de p = 2/60 = 1/30. Necesita encontrar tal N cuando la probabilidad de que más de N usuarios estén conectados simultáneamente a la red no exceda 0.01. Estos cálculos se pueden resolver fácilmente en el sistema STATISTICA. Resolviendo el problema en STATISTICA. Paso 1. Abre el módulo Estadísticas básicas... Cree un archivo binoml.sta que contenga 110 observaciones. Nombra la primera variable BINOMIO, la segunda variable es VENENO. Paso 2. BINOMIO, Abrir la ventana Variable 1(ver figura). Ingrese la fórmula en la ventana como se muestra en la figura. Clic en el botón OK. Paso 3. Haciendo doble clic en el título VENENO, Abrir la ventana Variable 2(ver fig.) Ingrese la fórmula en la ventana como se muestra en la figura. Tenga en cuenta que estamos calculando el parámetro de la distribución de Poisson usando la fórmula = n × pag. Por lo tanto = 2000 × 1/30. Clic en el botón OK.
STATISTICA calculará las probabilidades y las escribirá en el archivo generado. Etapa 4. Desplácese por la tabla construida hasta los casos numerados 86. Verá que la probabilidad de que 86 o más de 2000 usuarios de la red trabajen simultáneamente durante una hora es 0.01347 si se usa la distribución binomial. La probabilidad de que 86 o más personas de 2000 usuarios de la red trabajen simultáneamente durante una hora es 0.01293 cuando se usa la aproximación de Poisson para la distribución binomial. Dado que necesitamos una probabilidad de no más de 0,01, 87 líneas serán suficientes para proporcionar la calidad de comunicación requerida. Se pueden obtener resultados similares utilizando la aproximación normal para la distribución binomial (¡échale un vistazo!). Tenga en cuenta que V. Feller no tenía a su disposición el sistema STATISTICA y utilizó tablas para la distribución binomial y normal. Usando el mismo razonamiento, se puede resolver el siguiente problema discutido por W. Feller. Se requiere verificar si se requerirán más o menos líneas para atender de manera confiable a los usuarios al dividirlos en 2 grupos de 1000 personas cada uno. Resulta que dividir a los usuarios en grupos requerirá 10 líneas adicionales para lograr el mismo nivel de calidad. También puede tener en cuenta el cambio en la intensidad de la conexión de red durante el día. Distribución geométrica Si se realizan pruebas independientes de Bernoulli y se cuenta el número de pruebas hasta que se produce el siguiente "éxito", entonces este número tiene una distribución geométrica. Por lo tanto, si lanzas una moneda, entonces el número de lanzamientos que debes hacer antes de que caiga el siguiente escudo de armas obedece a una ley geométrica. La distribución geométrica está determinada por la fórmula: F (x) = p (1-p) x-1 p es la probabilidad de éxito, x = 1, 2,3 ... El nombre de la distribución está asociado a una progresión geométrica. Entonces, la distribución geométrica establece la probabilidad de que el éxito llegue en un determinado paso. La distribución geométrica es un análogo discreto de la distribución exponencial. Si el tiempo cambia en cuantos, entonces la probabilidad de éxito en cada momento del tiempo se describe mediante una ley geométrica. Si el tiempo es continuo, entonces la probabilidad se describe mediante una ley exponencial o exponencial. distribución hipergeométrica Esta es una distribución de probabilidad discreta de una variable aleatoria X tomando valores enteros m = 0, 1,2,..., n con probabilidades: donde N, M y n son enteros no negativos y M<
N, n < N. La distribución hipergeométrica generalmente se asocia con una elección sin recurrencia y determina, por ejemplo, la probabilidad de encontrar exactamente m bolas negras en una muestra aleatoria de tamaño n de una población general que contiene N bolas, incluidas M negras y N - M blancas (ver , por ejemplo, la enciclopedia "Probabilidad y estadística matemática", Moscú: Gran Enciclopedia Rusa, p. 144). La expectativa matemática de la distribución hipergeométrica no depende de N y coincide con la expectativa matemática µ = np de la distribución binomial correspondiente. Dispersión de la distribución hipergeométrica Esta distribución es muy común en tareas de control de calidad. Distribución polinomial Una distribución polinomial o multinomial, naturalmente, generaliza la distribución. Si la distribución binomial ocurre cuando se lanza una moneda con dos resultados (enrejado o escudo de armas), entonces la distribución polinomial ocurre cuando se lanza un dado y hay más de dos resultados posibles. Formalmente, esta es la distribución de probabilidad conjunta de variables aleatorias X 1, ..., X k, tomando valores enteros no negativos n 1, ..., nk, satisfaciendo la condición n 1 + ... + nk = n, con probabilidades: El nombre "distribución polinomial" se explica por el hecho de que las probabilidades multinomiales surgen durante la expansión del polinomio (p 1 + ... + p k) n distribución beta La distribución beta tiene una densidad de la forma: La distribución beta estándar se concentra en el rango de 0 a 1. Aplicando transformaciones lineales, el valor beta se puede transformar para que tome valores en cualquier rango. Las principales características numéricas de una cantidad con una distribución beta: Distribución de valores extremos La distribución de valores extremos (tipo I) tiene una densidad de la forma: Esta distribución a veces también se denomina distribución extrema. La distribución de valores extremos se utiliza para modelar eventos extremos, como niveles de inundación, velocidades de vórtice, el máximo de índices bursátiles para un año determinado, etc. Esta distribución se utiliza en la teoría de la fiabilidad, por ejemplo, para describir el tiempo de fallo de los circuitos eléctricos, así como en los cálculos actuariales. distribución Rayleigh La distribución de Rayleigh tiene una densidad de la forma: donde b es el parámetro de escala. La distribución de Rayleigh se concentra en el rango de 0 a infinito. En lugar de 0, STATISTICA le permite ingresar otro valor para el parámetro de umbral, que se restará de los datos originales antes de ajustar la distribución de Rayleigh. Por lo tanto, el valor del parámetro de umbral debe ser menor que todos los valores observados. Si dos variables y 1 e y 2 son independientes entre sí y se distribuyen normalmente con la misma varianza, entonces la variable La distribución de Rayleigh se utiliza, por ejemplo, en la teoría del tiro. Distribución Weibull La distribución de Weibull lleva el nombre del investigador sueco Waloddi Weibull, quien usó esta distribución para describir diferentes tipos de tiempos de falla en la teoría de la confiabilidad. Formalmente, la densidad de distribución de Weibull se escribe en la forma: A veces, la densidad de distribución de Weibull también se escribe en la forma: B es el parámetro de escala; С - parámetro de forma; E es la constante de Euler (2.718...). Parámetro de posición. Normalmente, la distribución de Weibull se centra en el semieje de 0 a infinito. Si, en lugar del límite 0, introducimos el parámetro a, que a menudo es necesario en la práctica, surge la llamada distribución de Weibull de tres parámetros. La distribución de Weibull se usa ampliamente en la teoría de la confiabilidad y el seguro. Como se describió anteriormente, la distribución exponencial se usa a menudo como modelo para estimar MTBF bajo el supuesto de que la probabilidad de falla de una instalación es constante. Si la probabilidad de falla cambia con el tiempo, se aplica la distribución de Weibull. En c = 1 o, en otra parametrización, at, la distribución de Weibull, como es fácil de ver en las fórmulas, se transforma en una distribución exponencial, y at, en la distribución de Rayleigh. Se han desarrollado métodos especiales para estimar los parámetros de la distribución de Weibull (ver, por ejemplo, el libro: Lawless (1982) Statistical models and Methods for Lifetime Data, Belmont, CA: Lifetime Learning, que describe los métodos de estimación, así como los problemas que surgen al estimar el parámetro de posición para una distribución Weibull de tres parámetros). A menudo, al realizar un análisis de confiabilidad, es necesario considerar la probabilidad de falla dentro de un breve intervalo de tiempo después de un punto en el tiempo. siempre que hasta el momento No ocurrió ninguna falla. Esta función se denomina función de riesgo o función de tasa de fallas y se define formalmente de la siguiente manera: H (t) - función de tasa de falla o función de riesgo en el tiempo t; f (t) - densidad de distribución de los tiempos de falla; F (t) - función de distribución de tiempos de falla (integral de densidad sobre el intervalo). En términos generales, la función de tasa de fallas se escribe de la siguiente manera: Cuando la función de riesgo es igual a una constante, que corresponde al funcionamiento normal del dispositivo (ver fórmulas). En, la función de riesgo disminuye, lo que corresponde al rodaje del dispositivo. En, la función de riesgo disminuye, lo que corresponde al envejecimiento del dispositivo. Las funciones de riesgo típicas se muestran en el gráfico. Los diagramas de densidad de Weibull con diferentes parámetros se muestran a continuación. Es necesario prestar atención a tres rangos de valores del parámetro a: En la primera área, la función de riesgo disminuye (período de ajuste), en la segunda área, la función de riesgo es igual a una constante, en la tercera área, la función de riesgo aumenta. Puede comprender fácilmente lo que se ha dicho para el ejemplo de comprar un automóvil nuevo: primero hay un período de adaptación del automóvil, luego un largo período de funcionamiento normal, luego las piezas del automóvil se desgastan y el riesgo de falla aumenta considerablemente. . Es importante que todos los periodos de funcionamiento puedan ser descritos por la misma familia de distribución. Esta es la idea de la distribución de Weibull. Estas son las principales características numéricas de la distribución de Weibull. Distribución de Pareto En varios problemas de estadística aplicada, a menudo se encuentran las llamadas distribuciones truncadas. Por ejemplo, esta distribución se utiliza en los seguros o en la fiscalidad cuando interesan rentas que superan un determinado valor c 0 Las principales características numéricas de la distribución de Pareto: distribución logística La distribución logística tiene una función de densidad: A - parámetro de posición; B es el parámetro de escala; E es el número de Euler (2,71...). Hotelling T 2 -distribución Esta distribución continua, concentrada en el intervalo (0, T), tiene una densidad: donde los parametros nyk, n>_k>_1, se denominan grados de libertad. En k de Hotelling = 1, la distribución P se reduce a la distribución de Student, y para cualquier k> 1 puede considerarse como una generalización de la distribución de Student al caso multidimensional. La distribución de Hotelling se basa en la distribución normal. Sea un vector aleatorio Y de k dimensión que tenga una distribución normal con vector de media cero y matriz de covarianza. Considere el valor donde los vectores aleatorios Z i son independientes entre sí e Y y se distribuyen de la misma forma que Y. Entonces la variable aleatoria T 2 = Y T S -1 Y tiene la distribución T 2-Hotelling con n grados de libertad (Y es un vector columna, T es el operador de transposición). donde la variable aleatoria t n tiene una distribución de Student con n grados de libertad (ver "Probabilidad y estadística matemática", Encyclopedia, p. 792). Si Y tiene una distribución normal con una media distinta de cero, entonces la distribución correspondiente se llama descentrado Hotelling T 2 -distribución con n grados de libertad y parámetro de no centralidad v. La distribución T 2 de Hotelling se utiliza en estadística matemática en la misma situación que la distribución t de Student, pero solo en el caso multidimensional. Si los resultados de las observaciones X 1, ..., X n son vectores aleatorios independientes normalmente distribuidos con un vector medio µ y una matriz de covarianza no degenerada, entonces las estadísticas tiene una distribución Hotelling T 2 con n - 1 grados de libertad. Este hecho forma la base del criterio de Hotelling. En STATISTICA, el criterio de Hotelling está disponible, por ejemplo, en el módulo Estadísticas y tablas básicas (ver el cuadro de diálogo a continuación). distribución Maxwell La distribución de Maxwell surgió en física al describir la distribución de las velocidades de las moléculas de un gas ideal. Esta distribución continua está centrada en (0,) y tiene una densidad: La función de distribución tiene la forma: donde Ф (x) es la función de distribución normal estándar. La distribución de Maxwell tiene un coeficiente de asimetría positivo y una sola moda en un punto (es decir, la distribución es unimodal). La distribución de Maxwell tiene momentos finitos de cualquier orden; la expectativa matemática y la varianza son iguales, respectivamente, y La distribución de Maxwell está naturalmente relacionada con la distribución normal. Si X 1, X 2, X 3 son variables aleatorias independientes con distribución normal con parámetros 0 y х 2, entonces la variable aleatoria Distribución de Cauchy Esta sorprendente distribución a veces no tiene un valor medio, ya que su densidad tiende muy lentamente a cero al aumentar x en valor absoluto. Estas distribuciones se denominan distribuciones de colas pesadas. Si necesita encontrar una distribución que no tenga media, llame inmediatamente a la distribución de Cauchy. La distribución de Cauchy es unimodal y simétrica con respecto a la moda, que es simultáneamente la mediana y tiene una función de densidad de la forma: donde c> 0 es el parámetro de escala y a es el parámetro central, que determina simultáneamente los valores de la moda y la mediana. La integral de la densidad, es decir, la función de distribución viene dada por la relación: Distribución t de Student El estadístico inglés W. Gosset, conocido bajo el seudónimo de "Student" y que inició su carrera con un estudio estadístico de la calidad de la cerveza inglesa, obtuvo en 1908 el siguiente resultado. Dejar x 0, x 1, .., x m - independientes, (0, s 2) - variables aleatorias normalmente distribuidas: Esta distribución, ahora conocida como distribución t de Student (abreviada como distribuciones t (m), donde m es el número de grados de libertad), subyace en la famosa prueba t diseñada para comparar las medias de dos poblaciones. Función de densidad f t (x) no depende de la varianza х 2 de las variables aleatorias y, además, es unimodal y simétrica respecto al punto х = 0. Características numéricas básicas de la distribución de Student: La distribución t es importante cuando se consideran estimaciones de la media y se desconoce la varianza de la muestra. En este caso, se utilizan la varianza muestral y la distribución t. Con grandes grados de libertad (superiores a 30), la distribución t prácticamente coincide con la distribución normal estándar. El gráfico de la función de densidad de la distribución t se deforma con el aumento del número de grados de libertad de la siguiente manera: el pico aumenta, las colas se inclinan más hacia 0 y parece que los gráficos de la función de densidad de la distribución t se comprimen lateralmente. Distribución F Considerar m 1 + m 2 independientes y (0, s 2) cantidades normalmente distribuidas Obviamente, la misma variable aleatoria se puede definir como el cociente de dos cantidades distribuidas de chi-cuadrado independientes y apropiadamente normalizadas y, esto es El famoso estadístico inglés R. Fisher en 1924 demostró que la densidad de probabilidad de una variable aleatoria F (m 1, m 2) viene dada por la función: donde Γ (y) es el valor de la función gamma de Euler en. punto y, y la ley misma se denomina distribución F con los números de grados de libertad del numerador y el denominador iguales a m, 1 y m7, respectivamente Características numéricas básicas de la distribución F: La distribución F ocurre en discriminante, regresión y análisis de varianza, y otros tipos de análisis de datos multivariados.






T tiene una distribución exponencial con un parámetro (lambda). La distribución exponencial se usa a menudo para describir el intervalo entre eventos aleatorios sucesivos, como el intervalo entre visitas a un sitio impopular, ya que estas visitas son eventos raros.![]()




![]()





























![]()

![]()
![]()







![]() no excede la varianza de la distribución binomial npq. Para momentos de cualquier orden, la distribución hipergeométrica tiende a los valores correspondientes de los momentos de la distribución binomial.
no excede la varianza de la distribución binomial npq. Para momentos de cualquier orden, la distribución hipergeométrica tiende a los valores correspondientes de los momentos de la distribución binomial.



![]() tendrá una distribución de Rayleigh.
tendrá una distribución de Rayleigh.


![]()




















![]() tiene una distribución de Maxwell. Así, la distribución de Maxwell puede considerarse como la distribución de la longitud de un vector aleatorio, cuyas coordenadas en el sistema de coordenadas cartesianas en el espacio tridimensional son independientes y normalmente distribuidas con media 0 y varianza x 2.
tiene una distribución de Maxwell. Así, la distribución de Maxwell puede considerarse como la distribución de la longitud de un vector aleatorio, cuyas coordenadas en el sistema de coordenadas cartesianas en el espacio tridimensional son independientes y normalmente distribuidas con media 0 y varianza x 2.
![]()




![]() y pon
y pon



