Fiabilidad y significación estadística. Términos y conceptos básicos de estadística médica.
Significancia estadística
Los resultados obtenidos mediante un procedimiento de investigación específico se denominan estadísticamente significantesi la probabilidad de que ocurra accidentalmente es muy pequeña. Este concepto puede ilustrarse lanzando una moneda. Supongamos que se lanza una moneda 30 veces; El águila cayó 17 veces y las colas cayeron 13 veces. Lo hace significativodesviación de este resultado de lo esperado (15 pérdidas del "águila" y 15 - "colas"), ¿o es accidental esta desviación? Para responder a esta pregunta, puede, por ejemplo, lanzar la misma moneda muchas veces 30 veces seguidas, y observar cuántas veces se repetirá la proporción de "águilas" a "colas" igual a 17:13. El análisis estadístico nos salva de este tedioso proceso. Utilizándolo, después de los primeros 30 lanzamientos de monedas, puede evaluar el posible número de gotas aleatorias de 17 “águilas” y 13 “colas”. Tal evaluación se llama una declaración probabilística.
En la literatura científica sobre psicología industrial-organizacional, una expresión probabilística en forma matemática se denota por la expresión r(probabilidad)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (R< 0,01). Este hecho es importante para comprender la literatura, pero no debe considerarse que habla de la insensatez de hacer observaciones que no cumplen con estos estándares. Los llamados resultados de investigación insignificantes (observaciones que se pueden obtener por casualidad másuna o cinco de cada 100) puede ser muy útil para identificar tendencias y como guía para futuras investigaciones.
También se debe tener en cuenta que no todos los psicólogos están de acuerdo con los estándares y procedimientos tradicionales (por ejemplo, Cohen, 1994; Sauley y Bedeian, 1989). Los problemas relacionados con la medición en sí son el tema principal del trabajo de muchos investigadores que estudian la precisión de los métodos de medición y las premisas que subyacen a los métodos y estándares existentes, así como también desarrollan nuevos médicos y herramientas. Quizás algún día en el futuro, la investigación en este poder conducirá a un cambio en los estándares tradicionales para evaluar la significación estadística, y estos cambios serán reconocidos universalmente. (La Quinta División de la Asociación Americana de Psicología reúne a psicólogos especializados en el estudio de estimaciones, mediciones y estadísticas).
En informes de investigación, declaraciones probabilísticas como r< 0.05, asociado con algunos estadísticases decir, el número que se obtiene como resultado de un cierto conjunto de procedimientos matemáticos computacionales. La confirmación probabilística se obtiene al comparar estas estadísticas con datos de tablas especiales que se publican para este propósito. En la investigación psicológica industrial-organizacional, estadísticas como r, F, t, r\u003e(se lee chi cuadrado) y R(léase "múltiple R ").En cada caso, las estadísticas (un número) obtenidas como resultado del análisis de una serie de observaciones se pueden comparar con los números de la tabla publicada. Después de eso, podemos formular un enunciado probabilístico sobre la probabilidad de obtener accidentalmente este número, es decir, hacer una conclusión sobre la importancia de las observaciones.
Para comprender los estudios descritos en este libro, es suficiente tener una comprensión clara del concepto de significación estadística y no necesariamente saber cómo se calculan las estadísticas mencionadas anteriormente. Sin embargo, sería útil discutir una suposición que subyace en todos estos procedimientos. Esta es la suposición de que todas las variables observadas se distribuyen aproximadamente de acuerdo con la ley normal. Además, al leer informes sobre investigación psicológica industrial-organizacional, a menudo se encuentran tres conceptos más que juegan un papel importante: en primer lugar, la correlación y la correlación, en segundo lugar, la variable determinante / predictiva y "ANOVA" (análisis de varianza), En tercer lugar, un grupo de métodos estadísticos con el nombre general de "metaanálisis".
FUNCION PAGADA La función de significación estadística solo está disponible en algunos planes tarifarios. Comprueba si ella está adentro.
Puede averiguar si existen diferencias estadísticamente significativas en las respuestas recibidas de diferentes grupos de encuestados a las preguntas de la encuesta. Para trabajar con la función de significación estadística en SurveyMonkey debe:
- Habilite la función de significación estadística al agregar una regla de comparación a una pregunta en su encuesta. Seleccione grupos de encuestados para la comparación para ordenar los resultados de la encuesta por grupo para la comparación visual.
- Examine las tablas con datos sobre las preguntas de su encuesta para identificar la presencia de diferencias estadísticamente significativas en las respuestas recibidas de los diferentes grupos de encuestados.
Ver significancia estadística
Siguiendo los pasos a continuación, puede crear una encuesta que muestre significación estadística.
1. Agregar preguntas cerradas a la encuesta
Para mostrar la significación estadística durante el análisis de los resultados, deberá aplicar la regla de comparación a cualquier pregunta de su encuesta.
Puede aplicar la regla de comparación y calcular la significación estadística en las respuestas si utiliza uno de los siguientes tipos de preguntas en el diseño de la encuesta:
Debe asegurarse de que las opciones de respuesta propuestas se puedan dividir en grupos completos. Las opciones de respuesta que seleccione para la comparación al crear la regla de comparación se usarán para organizar los datos en tablas de referencias cruzadas a lo largo de la encuesta.
2. Reúna las respuestas.
Después de completar la encuesta, cree un recopilador para distribuirla. Hay varias formas
Debe obtener al menos 30 respuestas para cada opción de respuesta que planea usar en su regla de comparación para activar y ver la significación estadística.
Ejemplo de encuesta
Desea saber si los hombres están mucho más satisfechos con sus productos que las mujeres.
- Agregue dos preguntas de opción múltiple a la encuesta:
¿Cuál es su género? (Macho femenino)
¿Está satisfecho o insatisfecho con nuestro producto? (satisfecho), insatisfecho () - Asegúrese de que al menos 30 encuestados hayan elegido la respuesta "masculina" a la pregunta sobre género, y TAMBIÉN al menos 30 encuestados hayan elegido la opción "femenina" como su género.
- Agregue una regla de comparación a la pregunta "¿Cuál es su género?" y seleccione ambas opciones de respuesta como sus grupos.
- Use la tabla de datos debajo de la tabla para la pregunta "¿Está satisfecho o insatisfecho con nuestro producto?" para averiguar si alguna opción de respuesta muestra una diferencia estadísticamente significativa
¿Qué es una diferencia estadísticamente significativa?
Una diferencia estadísticamente significativa significa que mediante el análisis estadístico se estableció que existen diferencias significativas entre las respuestas de un grupo de encuestados y las respuestas de otro grupo. La significación estadística significa que los números obtenidos son significativamente diferentes. Tal conocimiento lo ayudará mucho con el análisis de datos. Sin embargo, usted determina la importancia de los resultados obtenidos. Es usted quien decide cómo interpretar los resultados de las encuestas y qué medidas deben tomarse en función de ellos.
Por ejemplo, recibe más quejas de compradores femeninos que de compradores masculinos. ¿Cómo determinar si tal diferencia es real y es necesario tomar medidas al respecto? Una de las mejores maneras de verificar sus observaciones es realizar una encuesta que le mostrará si los clientes masculinos están significativamente más satisfechos con su producto. Con la fórmula estadística, nuestra función de significación estadística le brindará la oportunidad de determinar si a los hombres realmente les gusta su producto mucho más que a las mujeres. Esto le permitirá tomar medidas basadas en hechos, no en conjeturas.
Diferencia estadísticamente significativa
Si sus resultados se resaltan en la tabla de datos, esto significa que los dos grupos de encuestados son significativamente diferentes entre sí. El término "significativamente" no significa que las cifras obtenidas tengan una importancia o significación particular, sino solo que existe una diferencia estadística entre ellas.
No hay diferencia estadísticamente significativa
Si sus resultados no están resaltados en la tabla de datos correspondiente, esto significa que, a pesar de la posible diferencia en las dos cifras comparadas, no hay diferencia estadística entre ellas.
Las respuestas sin diferencias estadísticamente significativas demuestran que no hay una diferencia significativa entre los dos elementos comparados cuando se utiliza el tamaño de la muestra, pero esto no significa necesariamente que no importen. Quizás al aumentar el tamaño de la muestra, puede identificar una diferencia estadísticamente significativa.
Tamaño de la muestra
Si tiene un tamaño de muestra muy pequeño, solo las diferencias muy grandes entre los dos grupos serán significativas. Si tiene un tamaño de muestra muy grande, las diferencias pequeñas y grandes se considerarán significativas.
Sin embargo, si los dos números son estadísticamente diferentes, esto no significa que la diferencia entre los resultados tenga un significado práctico para usted. Tendrá que decidir por sí mismo qué diferencias son significativas para su encuesta.
Cálculo de significancia estadística
Calculamos la significación estadística utilizando un nivel de confianza estándar del 95%. Si la opción de respuesta se muestra como estadísticamente significativa, esto significa que solo debido a la aleatoriedad o debido a un error de muestreo, la diferencia entre los dos grupos se produce con una probabilidad de menos del 5% (a menudo se muestra como: p<0,05).
Para calcular diferencias estadísticamente significativas entre grupos, utilizamos las siguientes fórmulas:
|
Parámetro |
Descripción | |
|---|---|---|
| a1 | La proporción de participantes del primer grupo que respondieron la pregunta de cierta manera, multiplicada por el tamaño de la muestra de este grupo. | |
| b1 | La proporción de participantes del segundo grupo que respondieron la pregunta de cierta manera, multiplicada por el tamaño de la muestra de este grupo. | |
| Cuota de muestra agrupada (p) | La combinación de dos lóbulos de ambos grupos. | |
| Error estándar (SE) | Un indicador de cuánto difiere su parte de la parte real. Un valor más bajo significa que la acción está cerca de la acción real, un valor mayor significa que la acción es significativamente diferente de la acción real. | |
| Estadística de prueba (t) | Estadística de prueba. El número de valores de desviación estándar en los que este valor difiere del valor promedio. | |
| Significancia estadística | Si el valor absoluto del estadístico de prueba excede 1.96 * desviaciones estándar del promedio, esto se considera una diferencia estadísticamente significativa. |
* 1.96 es el valor utilizado para un nivel de confianza del 95%, ya que el 95% del rango procesado por la función de distribución t de Student se encuentra dentro de 1.96 de la desviación estándar de la media.
Ejemplo de cálculo
Continuando con el ejemplo utilizado anteriormente, descubramos si el porcentaje de hombres que afirman estar satisfechos con su producto es en realidad significativamente mayor que el porcentaje de mujeres.
Digamos que 1000 hombres y 1000 mujeres participaron en su encuesta, y como resultado de la encuesta resultó que el 70% de los hombres y el 65% de las mujeres dicen que están satisfechos con su producto. ¿Está el indicador del 70% muy por encima del indicador del 65%?
Sustituya los siguientes datos de la encuesta en las fórmulas propuestas:
- p1 (% de hombres satisfechos con el producto) \u003d 0.7
- p2 (% de mujeres satisfechas con el producto) \u003d 0,65
- n1 (número de hombres encuestados) \u003d 1000
- n2 (número de mujeres encuestadas) \u003d \u200b\u200b1000
Dado que el valor absoluto del estadístico de prueba es mayor a 1.96, esto significa que la diferencia entre hombres y mujeres es significativa. En comparación con las mujeres, es más probable que los hombres estén satisfechos con su producto.
Ocultar significancia estadística
Cómo ocultar la significación estadística para todos los problemas
- Haga clic en la flecha hacia abajo a la derecha de la regla de comparación en la barra lateral izquierda.
- Seleccione un artículo Editar regla.
- Deshabilitar la función Mostrar significación estadística usando el interruptor.
- presiona el botón Aplicar.
Para ocultar el significado estadístico de una pregunta, debe:
- presiona el botón Melodía arriba de la tabla de esta pregunta.
- Abrir pestaña opciones de pantalla.
- Desmarca la casilla junto a Significancia estadística.
- presiona el botón Salvar.
La opción de visualización se activa automáticamente cuando se activa la visualización de significación estadística. Si desmarca esta opción de visualización, la visualización de significación estadística también se desactivará.
Active la función de significación estadística al agregar una regla de comparación a una pregunta en su encuesta. Examine las tablas de datos de su encuesta para identificar diferencias estadísticamente significativas en las respuestas recibidas de diferentes grupos de encuestados.
El nivel de significación en las estadísticas es un indicador importante que refleja el grado de confianza en la precisión y la verdad de los datos recibidos (pronosticados). El concepto es ampliamente utilizado en varios campos: desde la realización de investigaciones sociológicas, hasta la prueba estadística de hipótesis científicas.
Definición
El nivel de significación estadística (o resultado estadísticamente significativo) muestra cuál es la probabilidad de una ocurrencia accidental de los indicadores estudiados. La significación estadística general del fenómeno se expresa mediante el coeficiente valor p (nivel p). En cualquier experimento u observación, es probable que los datos obtenidos se deban a errores de muestreo. Esto es especialmente cierto para la sociología.
Es decir, una estadística es estadísticamente significativa cuya probabilidad de ocurrencia accidental es extremadamente pequeña o tiende a extremos. Extremo en este contexto se considera el grado de desviación de las estadísticas de la hipótesis nula (una hipótesis que se verifica para verificar su coherencia con los datos de muestra obtenidos). En la práctica científica, el nivel de significación se elige antes de la recopilación de datos y, por regla general, su coeficiente es 0.05 (5%). Para sistemas donde los valores precisos son extremadamente importantes, este indicador puede ser 0.01 (1%) o menos.

Antecedentes
El concepto de nivel de significancia fue introducido por el estadístico y genetista británico Ronald Fisher en 1925 cuando desarrolló una metodología para probar hipótesis estadísticas. Al analizar un proceso, hay una cierta probabilidad de ciertos fenómenos. Surgen dificultades cuando se trabaja con probabilidades de porcentaje pequeñas (o no obvias) que se enmarcan en el concepto de "error de medición".
Al trabajar con estadísticas que no son lo suficientemente específicas para probar, los científicos se enfrentaron con el problema de la hipótesis nula, que "interfiere" con pequeñas cantidades. Fisher propuso que dichos sistemas determinen la probabilidad de eventos al 5% (0.05) como una porción selectiva conveniente que permite rechazar la hipótesis nula en los cálculos.

La introducción de un coeficiente fijo
En 1933, los científicos Jerzy Neumann y Egon Pearson en sus trabajos recomendaron por adelantado (antes de la recopilación de datos) establecer un cierto nivel de importancia. Los ejemplos del uso de estas reglas son claramente visibles durante la elección. Supongamos que hay dos candidatos, uno de los cuales es muy popular y el segundo es poco conocido. Obviamente, el primer candidato gana las elecciones, y las posibilidades del segundo tienden a cero. Se esfuerzan, pero no son iguales: siempre existe la probabilidad de fuerza mayor, información sensacional, decisiones inesperadas que pueden cambiar los resultados electorales predichos.
Neumann y Pearson acordaron que el nivel de significancia propuesto de Fisher de 0.05 (indicado por el símbolo α) es lo más conveniente. Sin embargo, el propio Fisher en 1956 se opuso a la fijación de este valor. Él creía que el nivel de α debería establecerse de acuerdo con circunstancias específicas. Por ejemplo, en física de partículas, es 0.01.

Valor p
El término valor p se utilizó por primera vez en el trabajo de Brownley en 1960. El nivel P (valor p) es un indicador que está inversamente relacionado con la verdad de los resultados. El valor p del coeficiente más alto corresponde al nivel más bajo de confianza en la muestra de la dependencia entre las variables.
Este valor refleja la probabilidad de errores asociados con la interpretación de los resultados. Suponga que p-level \u003d 0.05 (1/20). Muestra la probabilidad del cinco por ciento de que la relación entre las variables encontradas en la muestra es solo una característica aleatoria de la muestra. Es decir, si esta dependencia está ausente, con repetidos experimentos, en promedio, en cada vigésimo estudio, uno puede esperar la misma o mayor dependencia entre las variables. A menudo, el nivel p se considera como el "margen aceptable" del nivel de error.
Por cierto, el valor p puede no reflejar la dependencia real entre las variables, sino que solo muestra un cierto valor promedio dentro de los supuestos. En particular, el análisis final de los datos también dependerá de los valores seleccionados de este coeficiente. Con un nivel de p \u003d 0.05, habrá algunos resultados, y con un coeficiente de 0.01, otros.

Prueba de hipótesis estadísticas
El nivel de significación estadística es especialmente importante cuando se prueban hipótesis. Por ejemplo, cuando se calcula una prueba de dos lados, el área de rechazo se divide por igual en ambos extremos de la distribución de la muestra (en relación con la coordenada cero) y se calcula la verdad de los datos.
Supongamos que, al monitorear un determinado proceso (fenómeno), resulta que la nueva información estadística indica pequeños cambios en relación con los valores anteriores. Además, las discrepancias en los resultados son pequeñas, no obvias, pero importantes para el estudio. El dilema surge ante el especialista: ¿se están produciendo realmente los cambios o son estos errores de muestreo (mediciones inexactas)?
En este caso, la hipótesis nula se utiliza o se rechaza (todo se atribuye a un error o el cambio en el sistema se reconoce como un hecho consumado). El proceso de resolución del problema se basa en la relación de significancia estadística total (valor p) y nivel de significancia (α). Si nivel p< α, значит, нулевую гипотезу отвергают. Чем меньше р-value, тем более значимой является тестовая статистика.
Valores utilizados
El nivel de significación depende del material que se analiza. En la práctica, se utilizan los siguientes valores fijos:
- α \u003d 0.1 (o 10%);
- α \u003d 0,05 (o 5%);
- α \u003d 0.01 (o 1%);
- α \u003d 0.001 (o 0.1%).
Cuanto más precisos sean los cálculos, menor será el coeficiente α utilizado. Naturalmente, los pronósticos estadísticos en física, química, farmacéutica y genética requieren una mayor precisión que en ciencias políticas, sociología.

Umbrales de relevancia en áreas específicas.
En áreas de alta precisión, como la física de partículas y las actividades de fabricación, la significación estadística a menudo se expresa como la relación de la desviación estándar (denotada por el coeficiente sigma - σ) en relación con la distribución de probabilidad normal (distribución gaussiana). σ es un indicador estadístico que determina la dispersión de valores de un cierto valor en relación con las expectativas matemáticas. Se usa para trazar la probabilidad de eventos.
Dependiendo del campo de conocimiento, el coeficiente σ varía mucho. Por ejemplo, al predecir la existencia del bosón de Higgs, el parámetro σ es cinco (σ \u003d 5), que corresponde al valor p \u003d 1 / 3.5 millones. En los estudios de genomas, el nivel de significancia puede ser 5 × 10 -8, lo cual no es raro para esto zona.
Eficiencia
Debe tenerse en cuenta que los coeficientes α y valor p no son características precisas. Cualquiera que sea el nivel de significación en las estadísticas del fenómeno estudiado, no es una base incondicional para aceptar la hipótesis. Por ejemplo, cuanto menor es el valor de α, mayor es la posibilidad de que la hipótesis establecida sea significativa. Sin embargo, existe un riesgo de error, lo que reduce el poder estadístico (importancia) del estudio.
Los investigadores que se centran únicamente en resultados estadísticamente significativos pueden llegar a conclusiones erróneas. Al mismo tiempo, es difícil verificar dos veces su trabajo, ya que ellos aplican supuestos (que, de hecho, son los valores de los valores α y p). Por lo tanto, siempre se recomienda, junto con el cálculo de la significación estadística, determinar otro indicador: la magnitud del efecto estadístico. La magnitud de un efecto es una medida cuantitativa de la fuerza de un efecto.
Más recientemente, Vladimir Davydov escribió una publicación en Facebook sobre pruebas A / B o MVT, lo que causó muchas preguntas.
Por lo general, realizar pruebas A / B o MVT en sitios es algo muy complicado. Aunque los "propietarios" parece que esto es elemental, porque "esto es lo máximo, hay programas especiales, gitanos".
Si decide probar el contenido web, recuerde:
1. Primero debe aislar una audiencia equivalente, igual, igual de calidad. Realizar pruebas A / A. La gran mayoría de las pruebas realizadas por agencias en línea o vendedores de Internet sin experiencia no son ciertas. Es por la razón de que el contenido se prueba en diferentes audiencias.
2. Realice docenas o mejores cientos de pruebas durante varios meses. Probar las opciones de la página 2-3 semanas no vale la pena.
3. Recuerde que puede probar en el formato MVT (es decir, muchas opciones), y no solo en A y B.
4. Analice estadísticamente la matriz de datos con los resultados de la prueba (en Excel, absolutamente bien, aún puede usar SPSS). Si los resultados están dentro del margen de error, cuánto se desvían y cómo dependen del tiempo. Si, por ejemplo, en el primer párrafo de la prueba A / A recibió desviaciones fuertes de una opción de otra, esto es un fracaso y no puede continuar con la prueba.
5. No es necesario probarlo todo. Esto no es entretenimiento (solo si realmente no tienes nada más que hacer). Las pruebas solo tienen sentido porque desde el punto de vista del marketing y el análisis comercial pueden conducir a resultados notables. Y también, cuyo resultado se puede medir realmente. Por ejemplo, decidió aumentar el tamaño de fuente en el sitio, probó una página con una fuente grande durante un par de semanas; las ventas aumentaron. ¿De qué está hablando esto? Aquí no hay nada para mí (ver párrafos anteriores).
6. Necesita probar toda la ruta. Es decir, no es suficiente tomar y probar la página de compra (o alguna acción en el sitio); debe probar esas páginas y los pasos que conducen a esta página de conversión final.
En los comentarios, se hizo la pregunta:
“¿Cómo establecer un ganador? Aquí probamos el título en la página que vende "de frente". ¿Cuál es la diferencia en la conversión entre A y B para reconocer al ganador?
Vladimir responde:
Primero, debe realizar largos experimentos aislados (la regla básica de cualquier evaluación estadística). En segundo lugar, inevitablemente se reduce a las estadísticas y las matemáticas (por lo tanto, recomiendo que excel y spss o análogos sean gratuitos). Necesitamos calcular la probabilidad de confianza de que la diferencia de valores signifique algo. Hay un buen artículo (uno de muchos). Allí toman transacciones de GA según las pruebas de Optimizely.https://www.distilled.net/uploads/ga_transactions.png compare las transacciones (compras) con la distribución de campana habitual y vea si el valor promedio cae dentro del intervalo de confianza del errorhttps://www.distilled.net/uploads/t-test_tool.png
¿Quieres recibir una oferta de nosotros?
Iniciar colaboraciónEl papel de la significación estadística en el aumento de la conversión: 6 cosas que debe saber
1. Exactamente lo que significa

"El cambio nos permitió lograr un aumento de conversión del 20% con un nivel de confianza del 90%". Desafortunadamente, esta afirmación no es en absoluto equivalente a otra, muy similar: "Las posibilidades de aumentar la conversión en un 20% son del 90%". Entonces, ¿de qué se trata realmente?
El 20% es el crecimiento que registramos de acuerdo con los resultados de las pruebas en una de las muestras. Si comenzamos a fantasear y conjeturar, podríamos suponer que este crecimiento se puede mantener constantemente, si continuamos probando indefinidamente. Pero esto no significa que con una probabilidad del 90% obtendremos un aumento del veinte por ciento en la conversión o un aumento de "al menos" al 20%, o "aproximadamente" al 20%.
90% es la probabilidad de que ocurra cualquier cambio en la conversión. En otras palabras, si realizamos diez pruebas A / B para obtener este resultado, y decidimos realizar las diez indefinidamente, entonces una de ellas (dado que la probabilidad de cambios es del 90%, entonces el 10% permanece sin cambios), probablemente , terminaría acercando el resultado "después de la prueba" a la conversión inicial, es decir, sin cambios. De las nueve pruebas restantes, algunas podrían mostrar un crecimiento de mucho menos del 20%. En otros, el resultado podría exceder esta barra.
Si estos datos se interpretan incorrectamente, corremos un gran riesgo al implementar la prueba. Es fácil alegrarse cuando la prueba muestra altas tasas de crecimiento de conversión con una probabilidad de confianza del 95%, pero sería más prudente no esperar demasiado hasta que la prueba llegue a su conclusión lógica.
2. Cuándo usar
Los candidatos más obvios son las pruebas divididas A / B, pero están lejos de ser los únicos. También puede probar diferencias estadísticamente significativas entre segmentos (por ejemplo, visitas a través de búsquedas regulares y pagas) o intervalos de tiempo (por ejemplo, abril de 2013 y abril de 2014).

Sin embargo, vale la pena señalar que esta correlación no implica una relación causal. Al realizar pruebas divididas, sabemos que podemos atribuir cualquier cambio en los resultados a aquellos elementos que distinguen las páginas, porque se presta especial atención para garantizar que el resto de la página sea completamente idéntico. Si compara grupos como los visitantes procedentes de búsquedas regulares y de pago, cualquier otro factor puede funcionar; por ejemplo, a partir de una búsqueda regular puede haber muchas visitas por la noche, y la conversión entre los visitantes nocturnos es muy alta. Las pruebas de significancia ayudan a determinar si un cambio tiene una razón, pero no pueden decir qué es exactamente.
3. Cómo probar los cambios en las tasas de conversión, fallas y salidas (tasa de salida)
Cuando observamos los "indicadores", de hecho, vemos los valores promediados de las variables binarias: alguien ha completado las acciones objetivo o no. Si tenemos una muestra de 10 personas con una tasa de conversión del 40%, en realidad miramos una tabla similar:

Necesitaremos esta tabla, junto con el promedio, para calcular la desviación promedio, un componente clave de significancia estadística. Sin embargo, el hecho de que cada valor en la tabla sea cero o uno hace que nuestra tarea sea más fácil: podemos hacerlo sin tener que copiar una gran lista de números, usando una calculadora para calcular la probabilidad de confianza de las pruebas A / B y comenzando por el conocimiento del indicador promedio y los tamaños muestreo. Esta es una herramienta de KissMetrics.

(¡Importante! Esta herramienta de cálculo tiene en cuenta solo un lado de la “campana” de la distribución de probabilidad. Para usar ambos lados y traducir el resultado a un significado de dos lados, debe duplicar la distancia desde el 100%; por ejemplo, el 95% de un lado se convierte en el 90% de dos lados).
A pesar de que la descripción dice "herramienta de confiabilidad de prueba A / B", también se puede usar para cualquier otra comparación de indicadores: simplemente reemplace la conversión con el indicador de fallas o salidas. Además, se puede usar para comparar segmentos o intervalos de tiempo: los cálculos serán los mismos.
Además, es adecuado para pruebas multivariadas (MVT): solo compare cada cambio individualmente con el original.
4. Cómo probar los cambios en la factura promedio
Para probar los valores promedio de variables no binarias, necesitamos un conjunto completo de datos, por lo que aquí todo es un poco más complicado. Por ejemplo, queremos establecer si existen diferencias significativas en el monto promedio de la orden para la prueba de división A / B; este punto a menudo se omite al optimizar la conversión, aunque para los indicadores comerciales es tan importante como la conversión misma.
Lo primero que necesitamos es obtener de Google Analytics una lista completa de transacciones para cada caso de prueba, para A y B (fue, se ha convertido). La forma más fácil de hacer esto es crear segmentos personalizados basados \u200b\u200ben variables personalizadas para su prueba dividida y luego exportar el informe de la transacción a una hoja de cálculo de Excel. Asegúrese de que todas las transacciones estén incluidas allí, no solo las 10 filas predeterminadas.

Cuando tiene dos listas de transacciones, puede copiarlas en una herramienta similar:
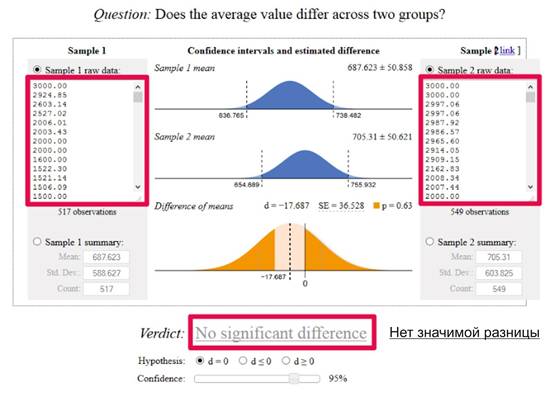
En el caso anterior, no tenemos un nivel de confianza en el nivel seleccionado del 95%. De hecho, si miramos la métrica "p" sobre el gráfico inferior de 0,63, queda claro que ni siquiera tenemos un 50% de importancia; existe una probabilidad del 63% de que la diferencia entre las métricas de la página sea pura coincidencia.
5. Cómo predecir la duración requerida de la prueba de división A / B
Evanmiller.org tiene otra herramienta conveniente de optimización de conversión: una calculadora de tamaño de muestra.
Esta herramienta le permite responder la pregunta "¿Cuánto tiempo se tarda en obtener resultados confiables de la prueba?" Y no debe tratar de adivinar esta respuesta.

Vale la pena señalar algunos puntos. En primer lugar, la herramienta tiene un cambio absoluto / relativo: si desea descubrir la diferencia entre una tasa de conversión básica del 5% y una tasa de conversión variable del 6%, será del 1% en términos absolutos (6-5 \u003d 1) o 20 % en términos relativos (6/5 \u003d 1.2). En segundo lugar, en la parte inferior de la página hay dos "controles deslizantes". El más bajo es responsable del nivel de significación requerido: si su objetivo es obtener una significación del 95%, el control deslizante debe establecerse en 5%. El control deslizante superior muestra la probabilidad de que el número de visitas a la página requeridas sea suficiente; por ejemplo, si desea conocer el número de visitas requeridas para lograr una probabilidad del ochenta por ciento de encontrar importancia en el 95%, configure el control deslizante superior en el 80% y el inferior en el 5%.
6. Lo que no es necesario hacer
Hay varias formas simples de identificar la inadecuación de una prueba dividida, que, sin embargo, están lejos de ser obvias a primera vista:
A) Prueba dividida de valores ordinales no binarios
Por ejemplo, su objetivo es averiguar si existe una diferencia significativa en la probabilidad de que los visitantes de los grupos "inicial" y "después de los cambios" compren ciertos productos. Usted marca los tres productos "1", "2" y "3", y luego ingresa estos valores en los campos de la prueba de significación. Desafortunadamente, este enfoque no funcionará: el producto 2 no es el promedio de los productos 1 y 3.
B) Configuración de distribución de tráfico

Al comienzo de la prueba, decide no correr riesgos y establece la distribución del tráfico en 90/10. Después de un tiempo, verá que el cambio no condujo a cambios notables en la conversión y mueve el control deslizante a un valor de 50/50. Pero los visitantes que regresan aún pertenecen a su grupo original, por lo que te encuentras en una situación en la que la versión previa al cambio tiene un mayor porcentaje de visitantes que regresan, lo que muestra una alta probabilidad de conversión. Las cosas se complican muy rápidamente, y la única forma fácil de obtener datos en los que puede confiar es considerar individualmente a los visitantes nuevos y recurrentes. Sin embargo, en este caso, llevará más tiempo obtener resultados significativos. E incluso si ambos subgrupos muestran resultados significativos, ¿qué pasa si uno de ellos realmente genera más visitantes recurrentes? En general, no necesita hacer esto y cambiar la distribución del tráfico durante la prueba.
C) Planificación
Parece obvio, pero no debe comparar los datos recopilados a la misma hora del día con los datos recopilados durante el día o en otro momento del día. Si desea realizar una prueba para una hora específica del día, tiene dos opciones.
1. Maneje las solicitudes de los visitantes, como siempre, durante todo el día, pero muéstreles la versión original de la página en ese momento del día en el que no esté interesado.
2. Compare manzanas con manzanas: si solo considera los datos sobre los cambios para la primera mitad del día, compárelos con los datos iniciales de la primera mitad del día.
Espero que algo de lo anterior sea útil para optimizar su conversión. Si tiene sus conocimientos, indíquelos en los comentarios.
Considere un ejemplo típico de la aplicación de métodos estadísticos en medicina. Los creadores de la droga sugieren que aumenta la diuresis en proporción a la dosis tomada. Para probar esta suposición, prescriben cinco dosis de la droga a cinco voluntarios.
De acuerdo con los resultados de las observaciones, se construye un gráfico de la dependencia de la diuresis de la dosis (Fig. 1.2A). La dependencia es visible a simple vista. Los investigadores se felicitan mutuamente por el descubrimiento y al mundo con un nuevo diurético.
De hecho, los datos solo indican de manera confiable que se observó diuresis dependiente de la dosis en estos cinco voluntarios. El hecho de que esta dependencia se manifieste en todas las personas que tomarán el medicamento no es más que
za

 de
de
zhenie No se puede decir que no tiene fundamento; de lo contrario, ¿por qué experimentar?
Pero la droga salió a la venta. Cada vez más personas lo toman con la esperanza de aumentar su diuresis. Y ¿qué vemos? Vemos la figura 1.2B, que indica la ausencia de cualquier conexión entre la dosis del medicamento y la diuresis. Los círculos negros indican los datos del estudio inicial. Las estadísticas tienen métodos para evaluar la probabilidad de obtener una muestra "no representativa", además, confusa. Resulta que, en ausencia de una relación entre la diuresis y la dosis del fármaco, la "dependencia" resultante se observaría en aproximadamente 5 de cada 1000 experimentos. Entonces, en este caso, los investigadores no tuvieron suerte. Si aplicaran incluso los métodos estadísticos más avanzados, aún así no los salvaría del error.
Este ejemplo ficticio, pero no muy alejado de la realidad, no citamos para indicar inutilidad
una estadística. Él habla sobre otra cosa, sobre la naturaleza probabilística de sus conclusiones. Como resultado de aplicar el método estadístico, no obtenemos la verdad última, sino solo una estimación de la probabilidad de un supuesto en particular. Además, cada método estadístico se basa en su propio modelo matemático y sus resultados son correctos en la medida en que este modelo corresponde a la realidad.
Fiabilidad y significación estadística:
- Diferencias estadísticamente significativas en los indicadores de calidad de vida.
- La población estadística. Signos contables. El concepto de investigación continua y selectiva. Requisitos para la población estadística y el uso de documentos contables y de informes.
- ENSAYO. INVESTIGACIÓN DE LA VALIDEZ DE LAS INDICACIONES DEL TONÓMETRO PARA MEDIR LA PRESIÓN EN LOS OJOS A TRAVÉS DEL OJO2018, 2018